Solving Rush Hour, the Puzzle July 2018
How I created a database of all interesting Rush Hour configurations.
Rush Hour is a 6x6 sliding block puzzle invented by Nob Yoshigahara in the 1970s. It was first sold in the United States in 1996.
I played a clone of this game on my first iPhone several years ago. Recently, I stumbled on the physical incarnation of it and instantly bought it on Amazon for my kids to play. We've been having fun with it, but naturally I was most interested in writing some code to solve the puzzles.
After writing a solver, I wrote a puzzle generator that would create more starting positions for us to try (the game comes with 40 levels printed on playing cards). The generator used simulated annealing to try to maximize the number of moves required to solve the puzzle.
Unsatisfied with the results, I then decided to try generating all possible puzzles. Ultimately I ended up with a complete database of every "interesting" starting position. It was quite challenging (and exciting!) and that's what I want to talk about in this article. My code is open source with a permissive license and the resulting database is available for download.

Rush Hour (Regular Edition)
Table of Contents
Terminology
- Piece: a vehicle on the puzzle board. Each piece has a position, a size, and an orientation (horizontal or vertical). In Rush Hour there are 2-pieces (cars) and 3-pieces (trucks).
- Primary Piece: the "red car" in the puzzle, the piece that must reach the exit on the right side of the board.
- Step: moving a piece by one unit.
- Move: moving a piece by N steps at once.
- Goal State: any state where the primary piece is on the target square (all the way to the right). Note that there's no need to model the primary piece actually exiting the board.
- Unsolved: a state that is further from a goal state than any other reachable state. The puzzle cannot be made any harder by moving the pieces around. Note that this does not mean unsolvable!
- Minimal: a state where each piece is important. No piece can be removed without altering the solution.
- Hardest: requiring the most moves to solve.
- Cluster: a set of puzzle states that are all reachable from one another - a connected graph of all reachable states.
- Wall: a fixed (unmovable), single-cell obstacle. Not part of the original Rush Hour game, but included in some clones and in my code.
Prior Art
I didn't do a whole lot of research or anything, but did find these papers:
- Finding hard initial configurations of Rush Hour with Binary Decision Diagrams - by Frédéric Servais
- On the Hardness of 6x6 Rush Hour - An exploration of the entire configuration space - by Jelle van Assema
The first one was rather academic and not particularly helpful. It seemed they were more interested in taking an unusual approach rather than just solving the problem. Also it was optimizing number of "steps" (versus "moves" - steps being unit moves) which seemed an unnatural way of thinking about it to me. The second was more interesting and gave me some ideas. But no where did I find any sort of complete database, just a handful of the hardest configurations and a few charts. The second paper mentioned that it took on the order of 100 hours for their code to run. My code takes about 3 hours.
Interesting Puzzles
So, what do I mean by "interesting"? I established a set of rules to filter out a lot of nonsense puzzles. Interesting puzzles follow these rules:
- No row may be completely filled with horizontal pieces and no column may be completely filled with vertical pieces. These just form walls of pieces that can never move. Not very interesting.
- No horizontal piece may appear on the primary row except for the primary piece itself. That would allow other cars to exit the board too. However, walls may be present to the left of the primary piece.
- There should only be one database entry per cluster - no two entries in the database should be reachable from one another.
- Database entries should be fully "unsolved" - they cannot be made any harder by moving pieces around.
- Database entries should be "minimal" - each piece in the puzzle is important. Removing any piece will alter the solution. (This rule drastically reduces the size of the database but adds some processing time.)
- The database should be complete - any cluster that satisfies the above rules should be included.
Combinatorial Explosion
Rush Hour is a perfect example of combinatorial explosion.
Board Size |
Time to Solve* |
Interesting Puzzles |
Number of States |
Number of States (One Wall) |
|---|---|---|---|---|
4x4 |
0.01s |
32 |
9,303 |
43,927 |
5x5 |
6.2s |
1,730 |
6,795,363 |
51,444,144 |
6x6 |
3h10m |
476,118 |
27,103,652,325 |
287,592,039,683 |
7x7 |
??? |
??? |
??? |
??? |
So, writing efficient code and using clever algorithms will be important but will only get us so far. I think solving the 7x7 case may be doable but would require extensive computing resources that I can't afford! (It would probably require decades of CPU time.) Even adding walls increases complexity significantly, so I have only solved the case of 0, 1, or 2 walls. Note that while there are tens of billions of possible states, there are only about half a million puzzles that meet our criteria of interesting-ness.
* times are from an iMac with a 3.4 GHz Intel Core i5 (4 cores)
Bitboards
My code uses bitboards heavily. These are commonly used in chess engines and for other board games. In the case of Rush Hour, the bitboards represent which squares are occupied by pieces. The code also maintains a bitboard for just horizontal pieces and a bitboard for just vertical pieces. There are 6x6 = 36 squares, so a 64-bit unsigned integer is used for the bitboards.
The following diagram shows which bits map to which squares.
00 01 02 03 04 05
06 07 08 09 10 11
12 13 14 15 16 17
18 19 20 21 22 23
24 25 26 27 28 29
30 31 32 33 34 35
The following diagram shows the bitboards for a sample board.
All Horz Vert GBB.L. 111010 011000 100010 GHI.LM 111011 000000 111011 GHIAAM => 111111 = 000110 | 111001 CCCK.M 111101 111000 000101 ..JKDD 001111 000011 001100 EEJFF. 111110 110110 001000
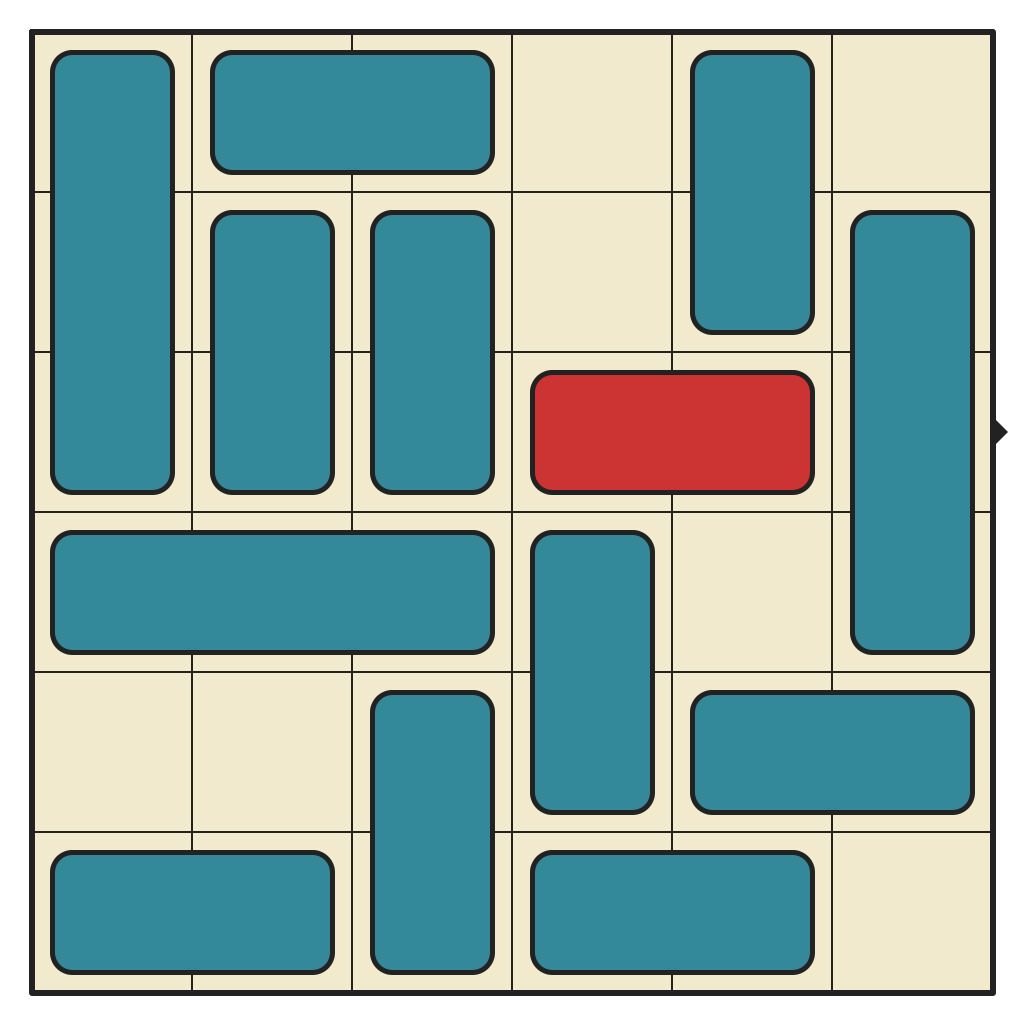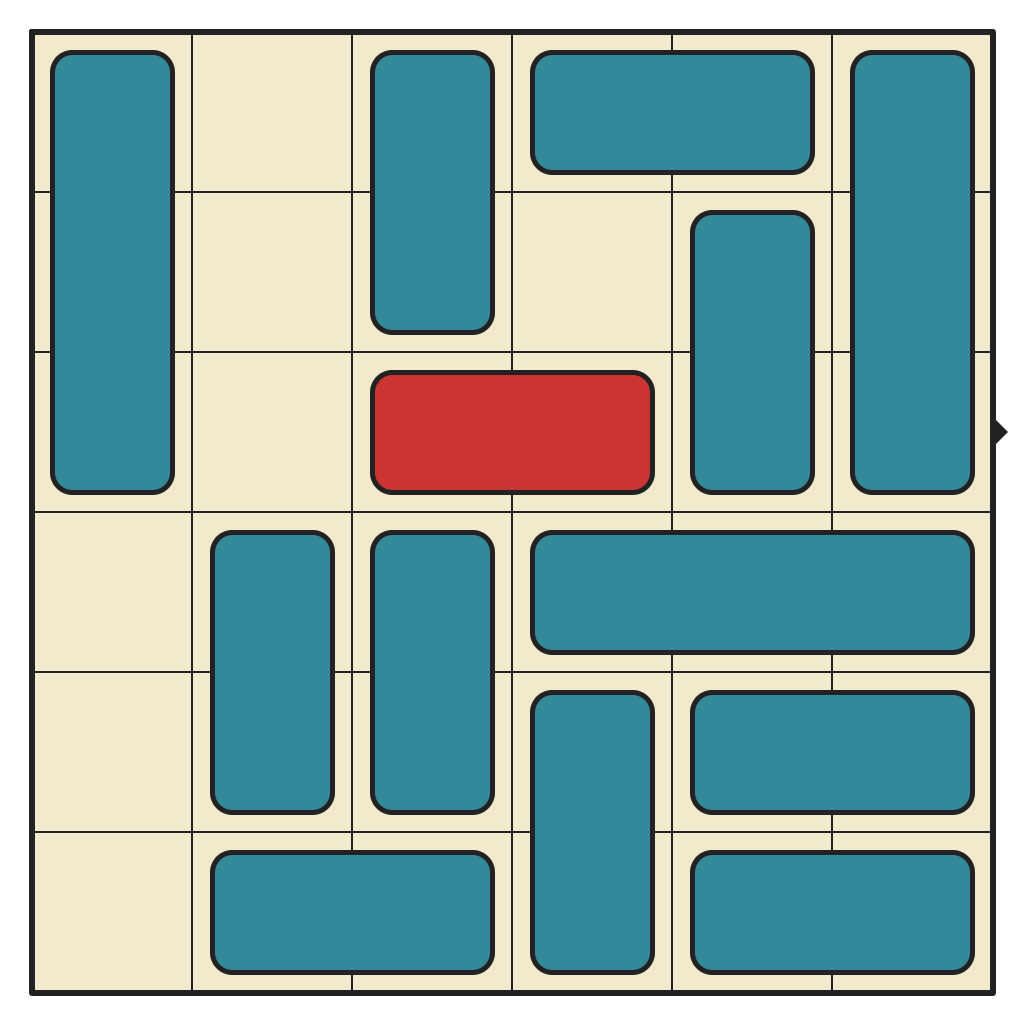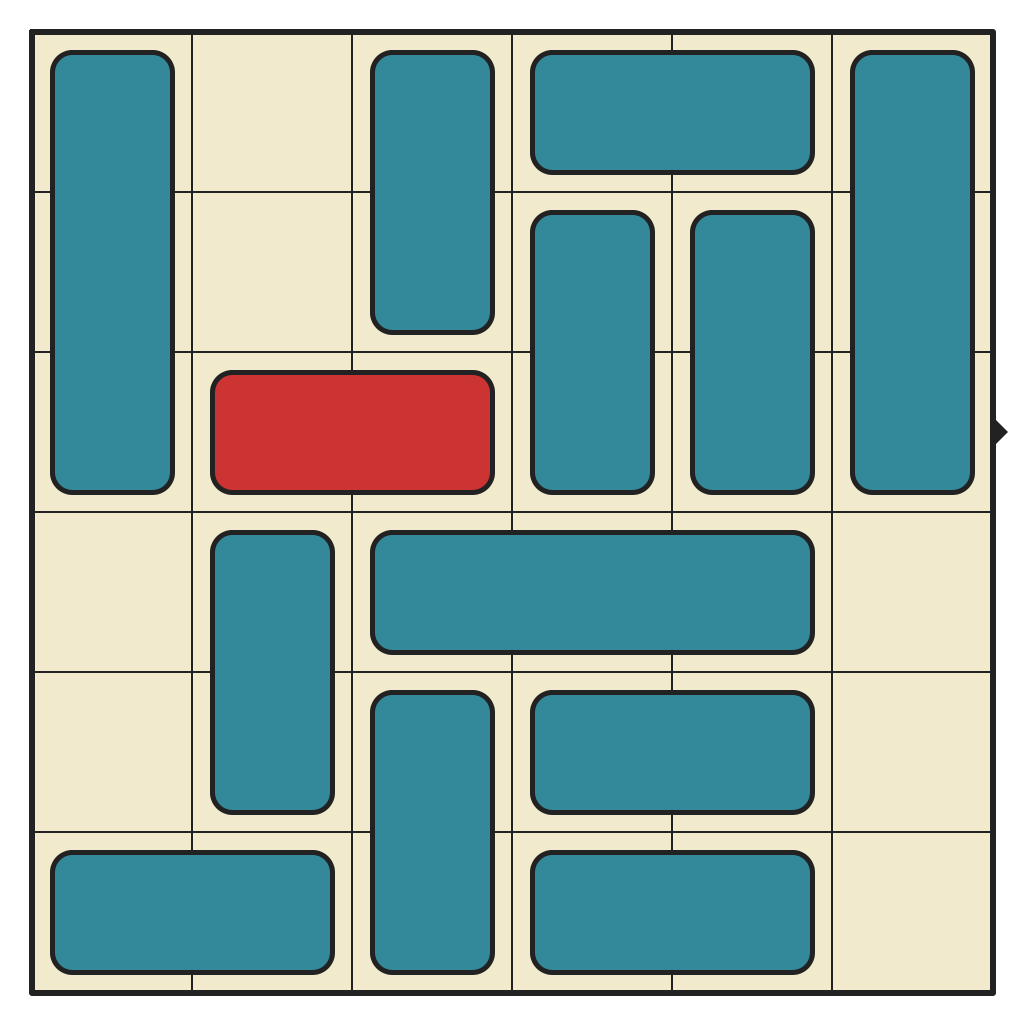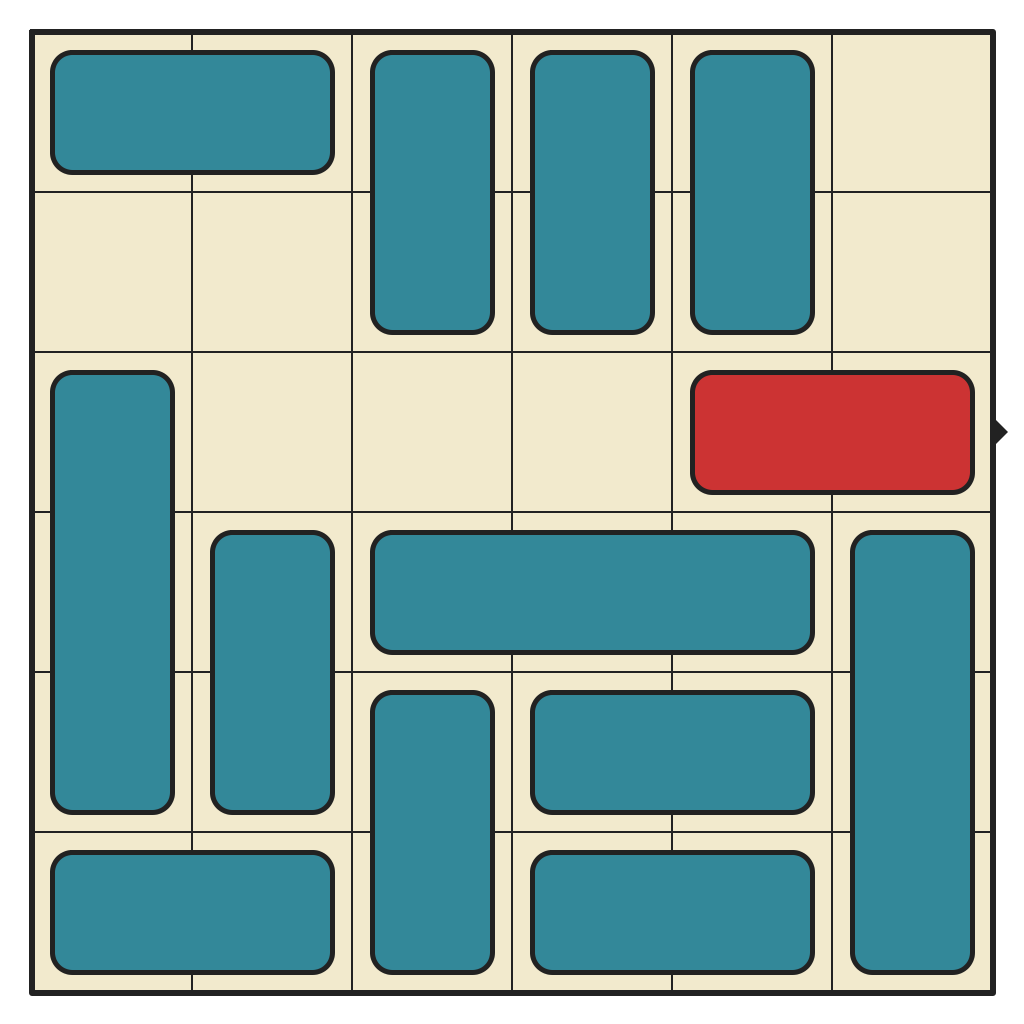
Solving a 51-move Puzzle
Enumerating States
To examine all possible puzzles, we need an efficient way to enumerate all possible piece placements based on our rules. Let's break it down by looking at individual rows and columns first. For the 6x6 puzzle with 2-pieces and 3-pieces, the following table shows all of the possible ways that horizontal pieces may appear on a row (or vertical pieces on a column).
[] |
[2] |
[2, 2] |
[2, 3] |
[3] |
[3, 2] |
|---|---|---|---|---|---|
...... |
AA.... |
AABB.. |
AABBB. |
AAA... |
AAABB. |
The primary row (the row with the red car) is special and is limited to the [2] set.
We can choose any of these placements for every row. But then when we begin choosing placements for the columns, we must check that we aren't making vertical pieces overlap the horizontal pieces. In my implementation, I use bitboards that are progressively updated as piece assignments are made to check for these collisions efficiently. As soon as a collision is identified, that subtree no longer needs to be considered.
Lexicographical Ordering
The enumeration scheme above will produce billions of states that we can then evaluate. But we only need to evaluate each distinct cluster (connected graph of mutually reachable states) once. We really only need the enumerator to give us one state per cluster, and then we can find the other reachable states during further evaluation.
In theory, we could maintain a giant set of seen positions to avoid duplicating work. But given the size of the search space I considered this a bad approach.
So I created the notion of having a single "canonical" state for each cluster. The canonical state is the one that compares less than every other reachable state. Less than, you may ask? Recall that the Board class maintains three bitboards, respectively indicating the presence of 1) all pieces, 2) horizontal pieces, and 3) vertical pieces. With these, defining the less-than operator is simple:
bool operator<(const Board &b1, const Board &b2) {
if (b1.HorzMask() == b2.HorzMask()) {
return b1.VertMask() < b2.VertMask();
}
return b1.HorzMask() < b2.HorzMask();
}
Simply comparing the All masks would not work, because two different states in the same cluster could have the same value.
So now, when evaluating a new cluster as a potential database entry, we can immediately exit early if we find that the initial state was not less than every other reachable state in the cluster. We trade in a small bit of processing time for a huge relief in memory consumption and inter-thread communication.
But there's more! We can make the enumerator smarter such that it usually produces canonical states that won't fail this check. If any piece can move up or to the left, then we know that some reachable state is less than the current state. Bitboards are put to good use here. As the enumerator is building up candidate states, it maintains a bitboard indicating squares that must be occupied to prevent any pieces from moving up or left. These are the squares immediately above vertical pieces and immediately to the left of horizontal pieces. Here's an example to demonstrate how just a few bitboard operations can identify if any pieces can move up or left. The standalone formula is: (((Horz >> 1) & ~RightColumn) | (Vert >> 6)) & ~All
H>>1&~RC V>>6 ~All GBB.L. 110000 111011 000101 000001 GHI.LM 000000 111001 000100 000000 GHIAAM => 001100 | 000101 & 000000 = 000000 CCCK.M 110000 001100 000010 000000 ..JKDD 000110 001000 110000 000000 EEJFF. 101100 000000 000001 000000
Shifting the horizontal mask by 1 emulates moving horizontal pieces to the left, but we must clear out the rightmost column due to the bits wrapping around. Shifting the vertical mask by the board width (6) emulates moving vertical pieces up. In this case we don't need to worry about wrapping. Finally, the & ~All operation removes bits that will be prevented from moving due to obstacles.
The result in this example is nonzero, so some piece is able to move up or left. (We can see that the M piece can move up.) This board is not canonical and can be skipped. (We'll visit this cluster when the enumerator produces the canonical form.)
Thanks to this technique, the code uses very little memory and doesn't need to maintain a huge lookup table of already-seen positions. In the 6x6 case, the enumerator produces perfectly "canonical" states 33% of the time. Without this trick it would be less than 1%.
Visualizing Clusters
Clusters are just directed graphs where each node is a puzzle state and each edge is a valid move. (Actually, all moves are reversible, so it could be considered an undirected graph as well.) So we can render them using Graphviz. Here are some examples (click to enlarge).

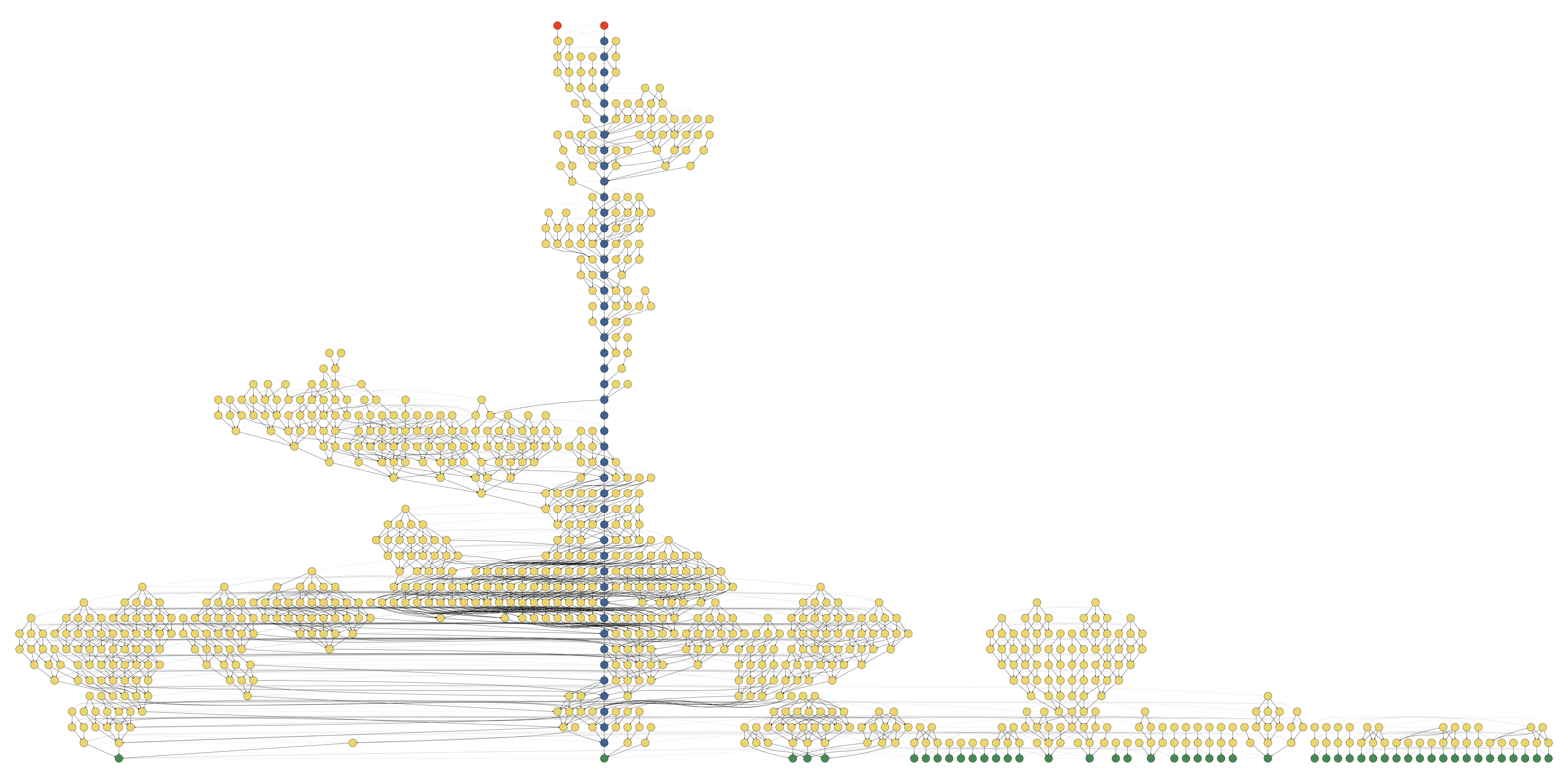

In these graphs, unsolved states are red, goal states are green, and an optimal shortest path is shown in blue. All other nodes are yellow. We can see that different clusters have different "shapes" and there are often bottleneck points. Perhaps this could somehow be used to estimate the difficulty of the puzzles?
Cluster Analysis
For each state produced by the enumerator, we want to analyze its cluster to figure out what we ultimately care about:
- Is this cluster solvable? That is, are any reachable states goal states? If not, we can abort early.
- Which state(s) are furthest from a goal state? That is, which states are most "unsolved"? How many moves are required to solve that state?
- Is the unsolved puzzle minimal? That is, are all of the pieces important? If removing any piece has no effect on the solution, then the puzzle is not minimal and is discarded.
- Bonus: how far from a goal state are all of the intermediate states? That is, what does the histogram look like with X being # of moves left and Y being # of states within the cluster. Stated yet another way, how many nodes appear on each rank in the Graphviz visualizations?
This part of the code is actually pretty simple. See cluster.cpp if you're interested!
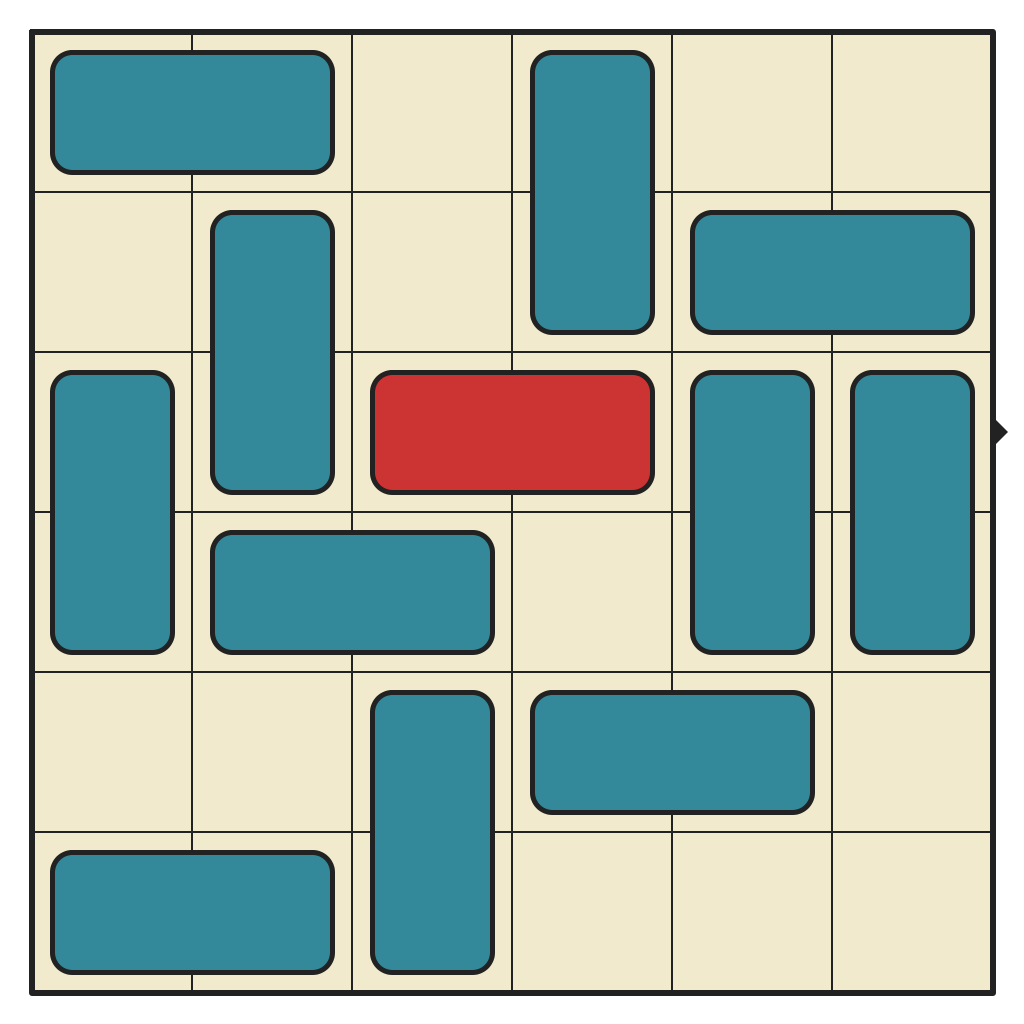
The largest cluster, by far. This puzzle has 541,934 reachable states. No 3-pieces and lots of space to move around. Only requires 15 moves to solve.
Go vs. C++
All of my code was initially written in Go. But when I started trying to "solve" the entire game I decided to use C++ to get the most performance possible.
I made a lot of improvements along the way in porting my code to C++, so I don't have a direct apples-to-apples comparison between Go and C++ for the full program. But I did run benchmarks on several sub-problems, such as repeatedly solving the same puzzle. In most of these benchmarks C++ came out about 2x faster than Go.
Special thanks to Matt Godbolt (of Compiler Explorer fame) for giving me some C++ performance tips!
The Cloud
Solving the 6x6 case with no walls took 3h10m on my iMac. But to compute puzzles with up to two walls, I used an EC2 instance with 72 cores (3.0 GHz Intel Xeon Scalable) to crank through it faster. It took 16h50m to complete and cost me about $50. But it sure was fun! I estimate it would have taken 170 hours (about one week) on my iMac.

htop on EC2 with 72 cores chugging away
Hardest Puzzles
Quantifying the difficulty of Rush Hour puzzles is... difficult... so normally when I say "hardest" I mean "requiring the most moves." I now present to you the hardest 6x6 puzzles with 0, 1, and 2 walls.
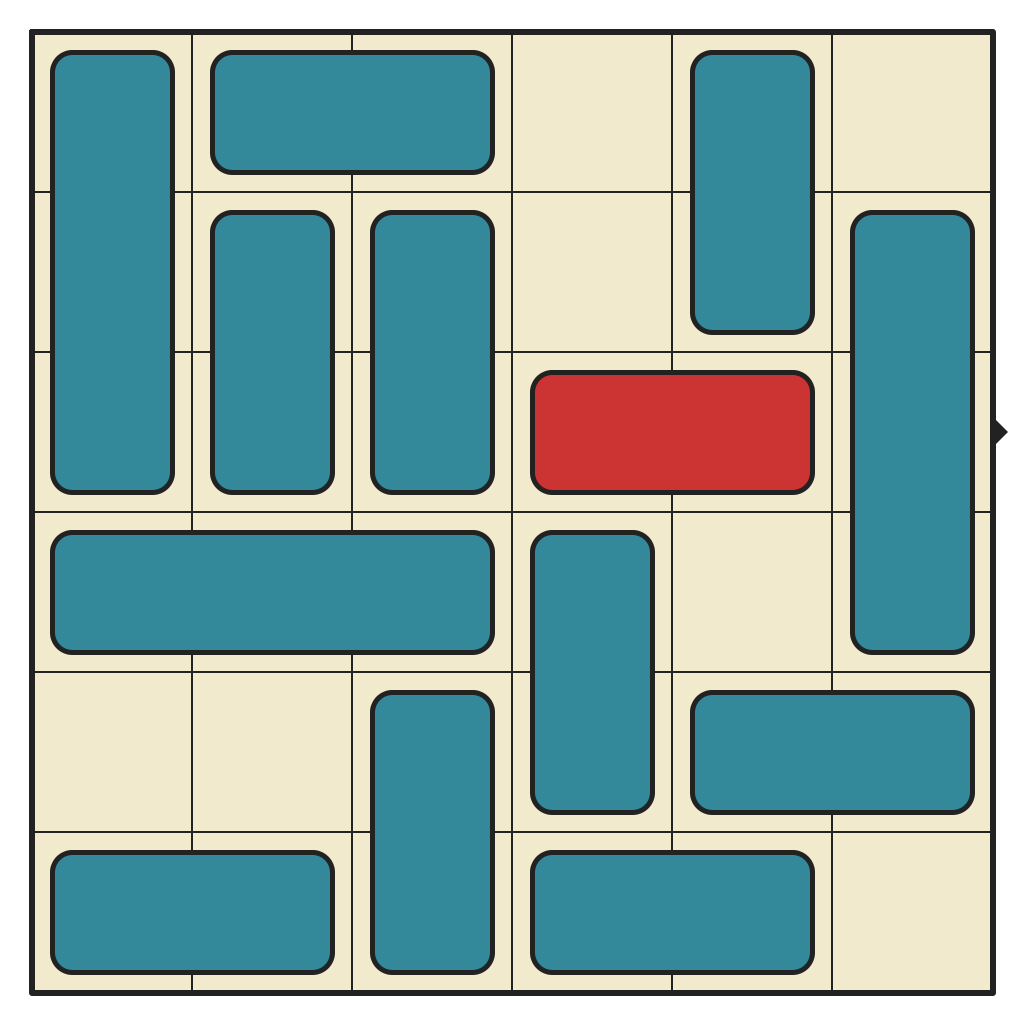
Hardest 6x6 with 0 walls, Requiring 51 Moves
(click for solution)
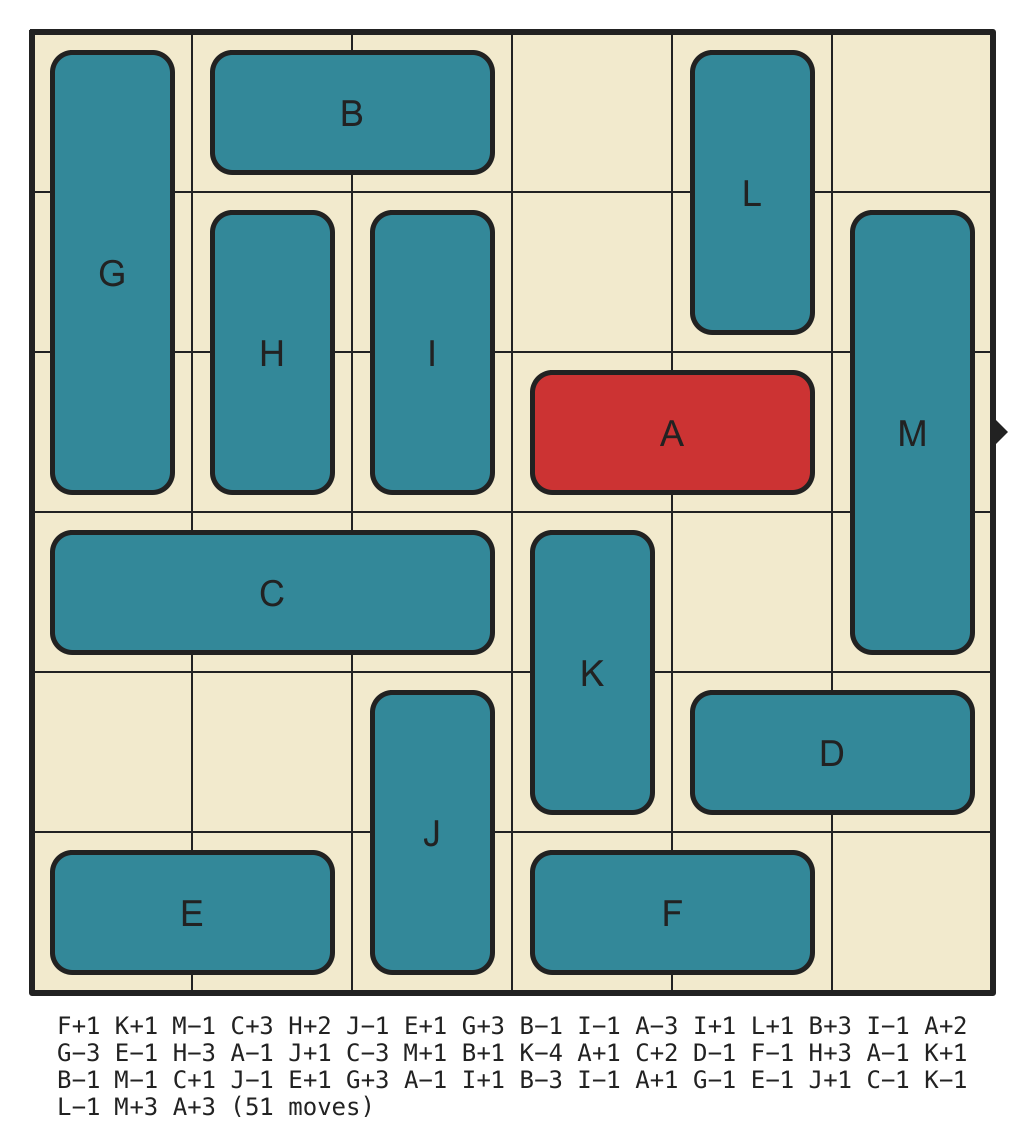{kind=link}
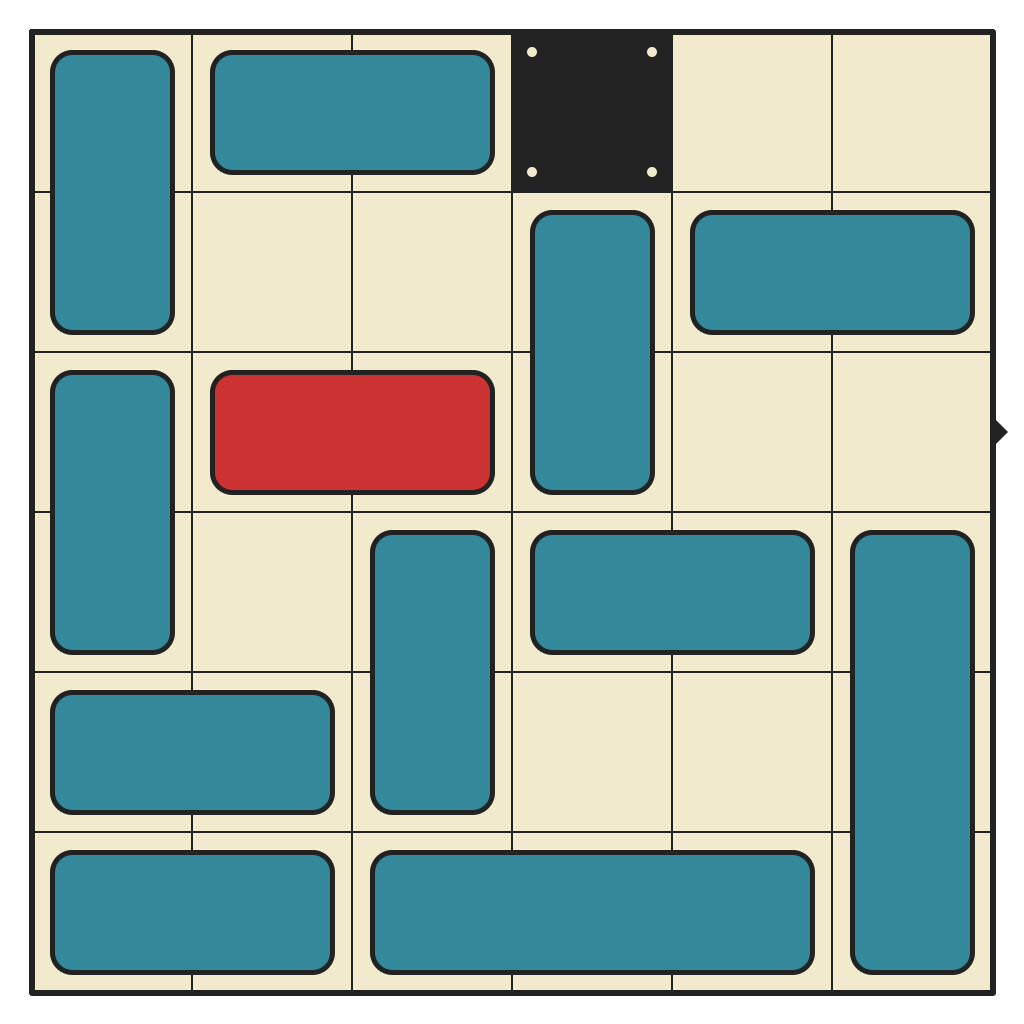
Hardest 6x6 with 1 wall, Requiring 60 Moves
(click for solution)
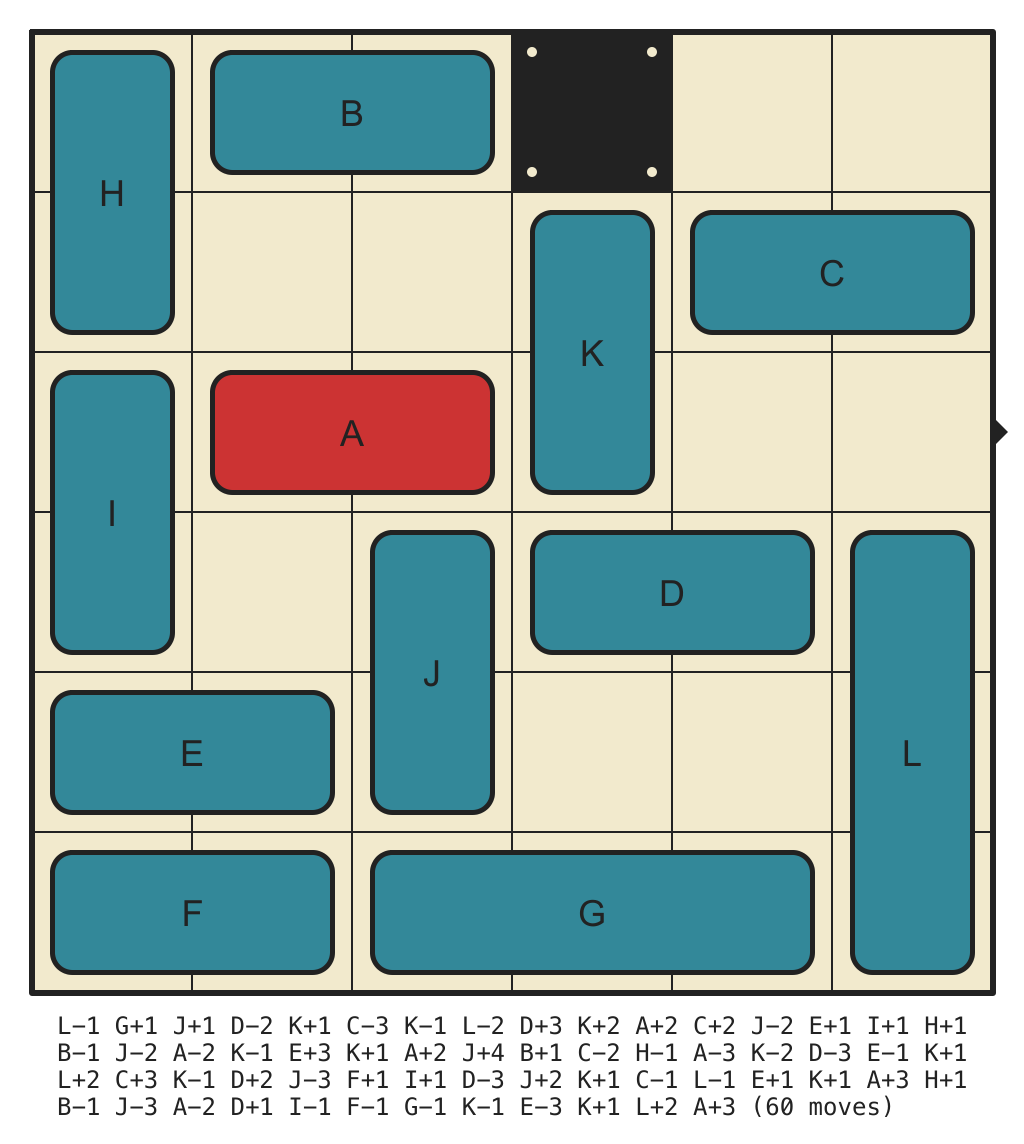{kind=link}
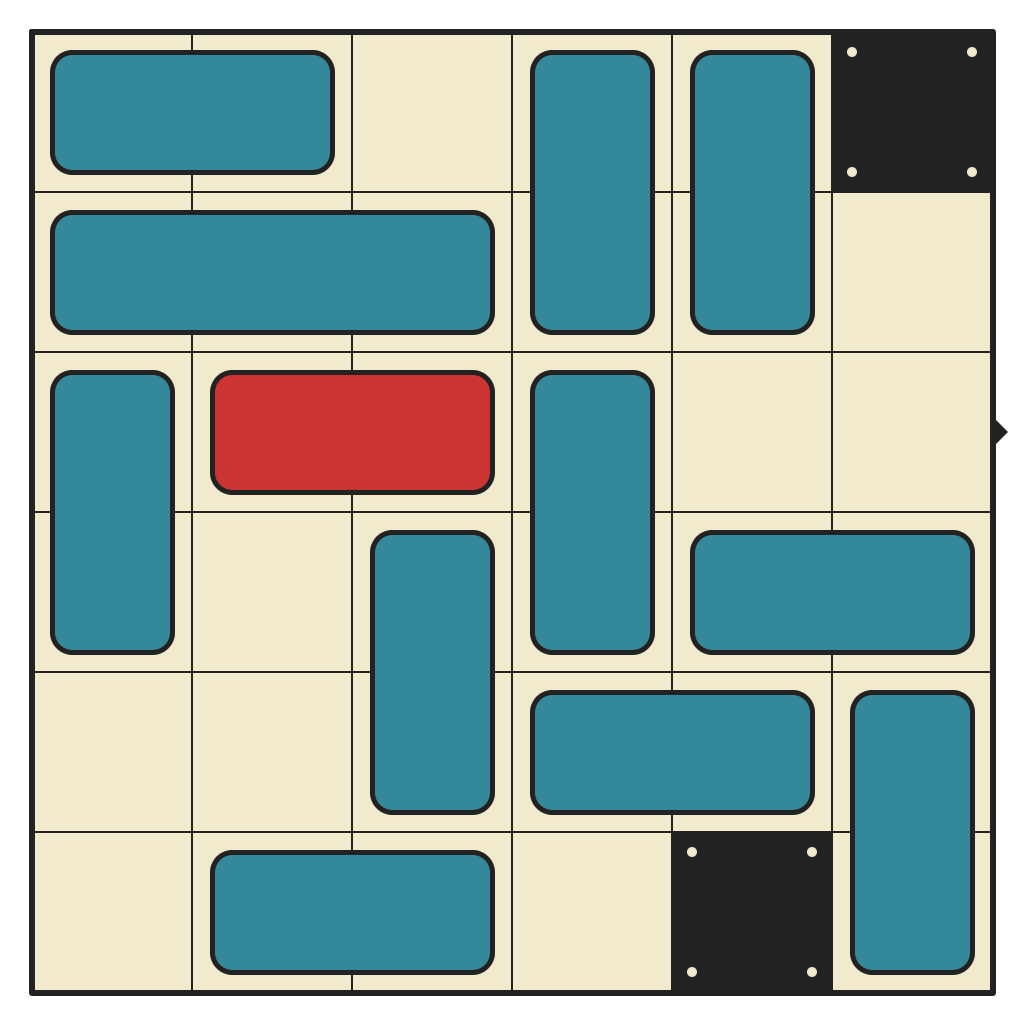
Hardest 6x6 with 2 walls, Requiring 58 Moves
(click for solution)
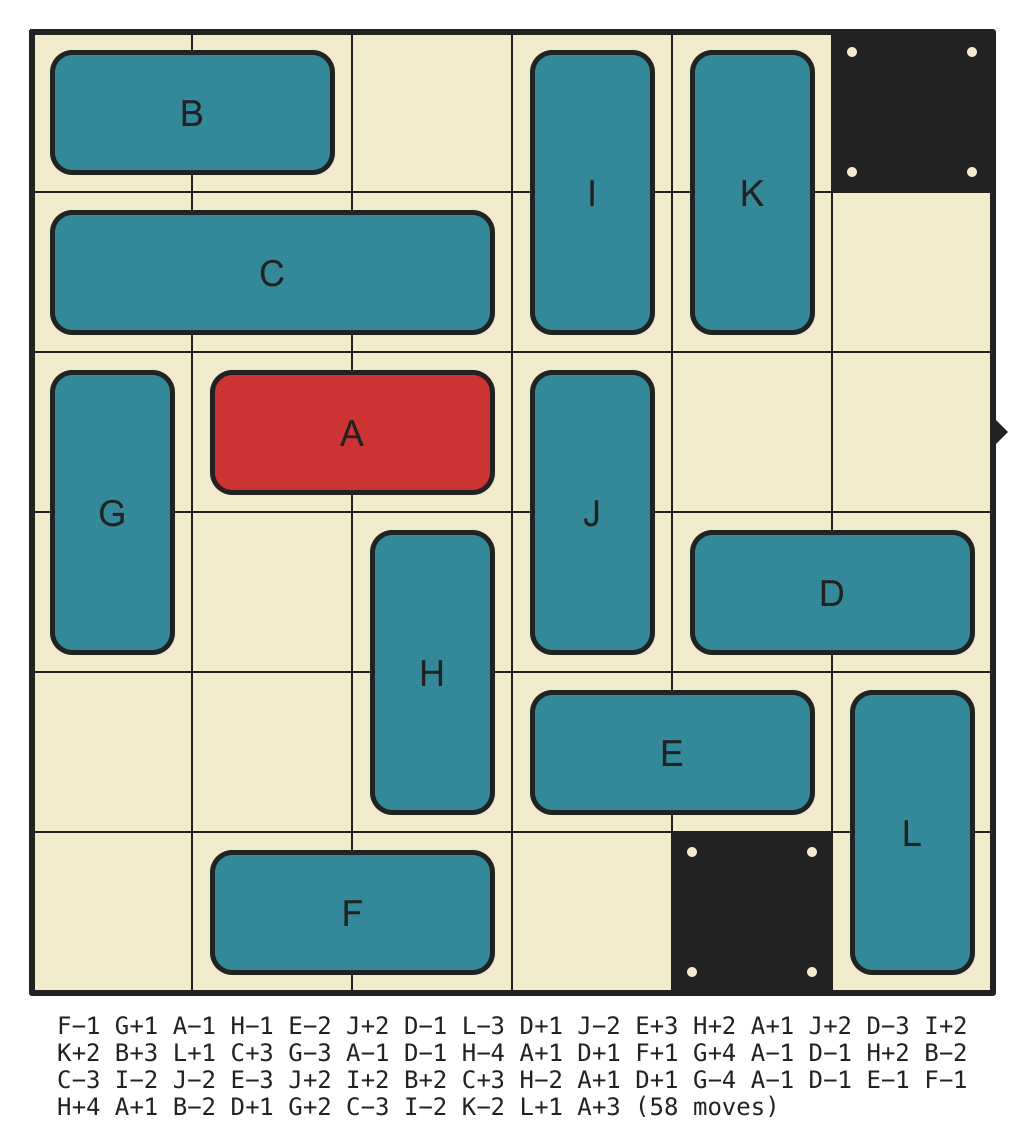{kind=link}
Analyzing the Results
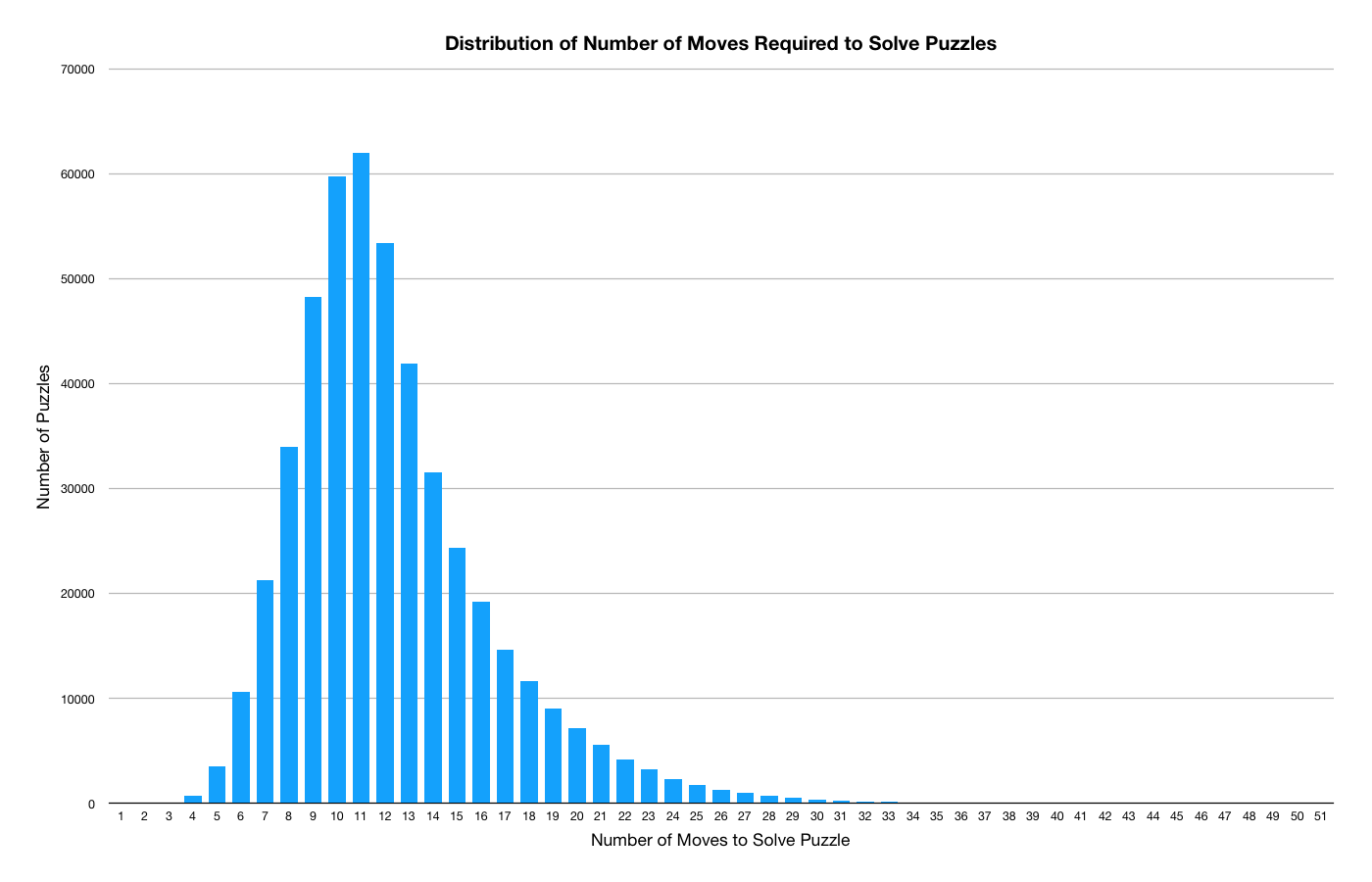
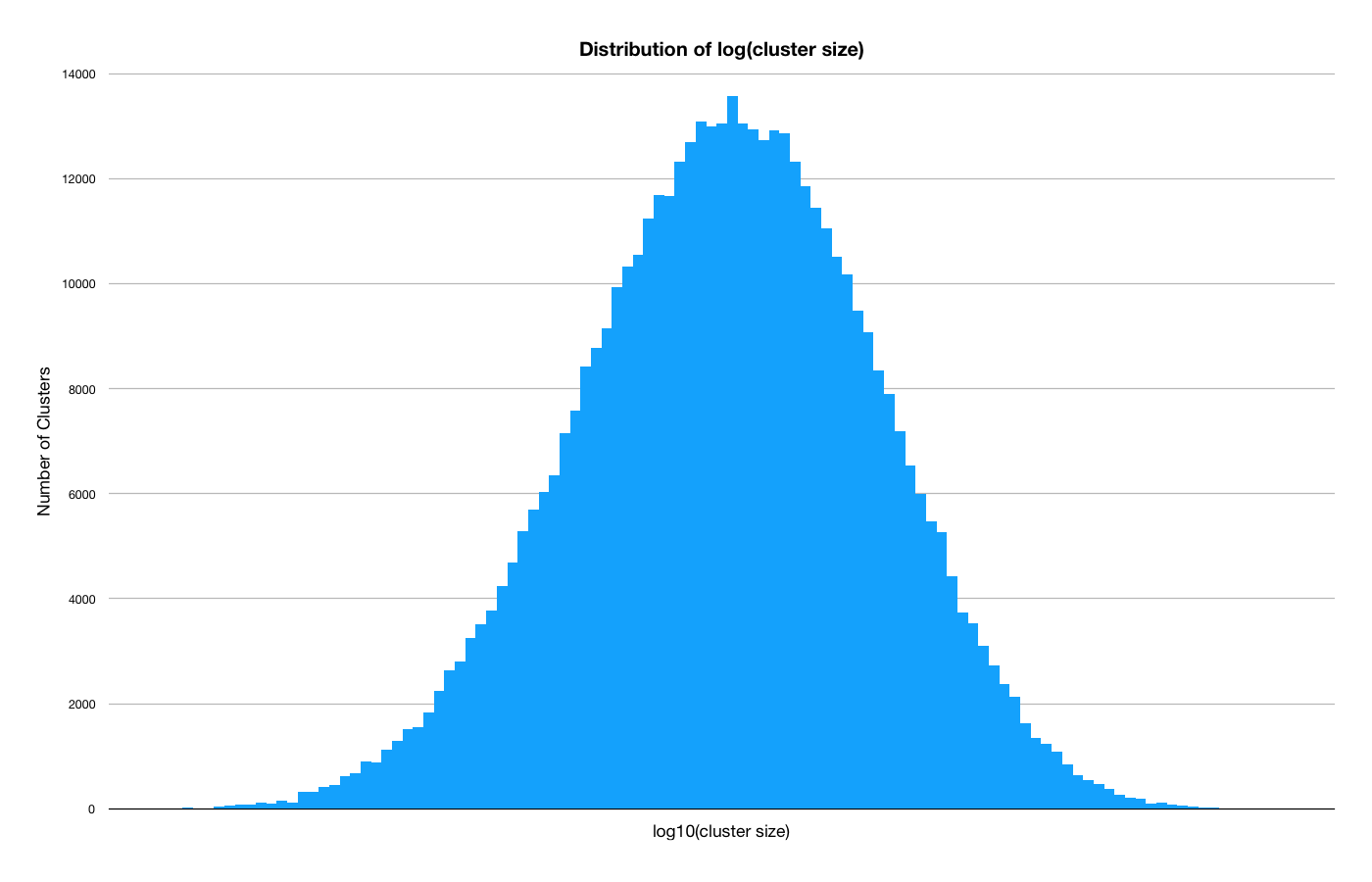
It is interesting to look at the cluster statistics in aggregate. The most common number of moves in the database is 11 and hard puzzles are rare. We see a very nice normal distribution when plotting log(cluster size). I didn't dive in too deeply here, so there might be more worth exploring.
Database Format
The database is a simple text file with just a few columns. There is one row for every valid (solvable, minimal) cluster. The columns are: # of moves, board description, and cluster size (# of reachable states).
60 IBBxooIooLDDJAALooJoKEEMFFKooMGGHHHM 2332 58 BBoKMxDDDKMoIAALooIoJLEEooJFFNoGGoxN 9192 55 ooBBMxDDDKMoAAJKoNooJEENIFFLooIGGLox 9712 55 ooBBMxDDDKMoAAJKoNooJEENIFFLooIGGLHH 8257 54 oxCCMoDDDKMoAAJKooooJLEEIFFLoNIGGoxN 6355 54 oooJLxCCCJLoHAAKooHoIKDDooIEEMoFFoxM 3461 54 oooJxoCCCJLoHAAKLoHoIKDDooIEEMoFFoxM 2948 54 BBBKCCDDoKoLIAAKoLIoJEEMFFJooMooxoHH 1845 53 BBBCCNDDoxMNJAAoMOJoKFFOGGKLooxIILoo 4705 53 ooBBoxDDDKooAAJKoMooJEEMIFFLooIGGLHH 4228 53 ooBBoxDDDKooAAJKoMooJEEMIFFLooIGGLox 4102 52 oxCCMNDDDKMNAAJKooooJEEoIFFLooIGGLox 7178 52 oxCCMNDDDKMNAAJKooooJLEEIFFLooIGGHHo 5717 51 xCCoLMooJoLMAAJoLNHIDDDNHIoKEExooKGG 9360 51 GBBoLoGHIoLMGHIAAMCCCKoMooJKDDEEJFFo 4780 50 BBIooMGHIoLMGHAALNGCCKoNooJKDDooJEEx 14385 50 ooIBBBooIKooAAJKoLCCJDDLGHEEoLGHFFoo 4643 50 ooooxoCCCJLoAAIJLMooIDDMHEEKooHFFKox 3874 50 ooooLxCCCJLoAAIJoMooIDDMHEEKooHFFKox 3676 50 ooooLxCCCJLoAAIJoMooIDDMHEEKooHFFKGG 3169 50 ooooxoCCCJLoAAIJLMooIDDMHEEKooHFFKGG 2966 50 ooxCCLDDoKoLIAAKooIoJKEEFFJooMGGGHHM 1845 50 BBBJCCHooJoKHAAJoKooIDDLEEIooLooxoGG 1066
The board description is a 36-character string representing the state of the unsolved board. It is a 6x6 2D array in row-major order. The characters in the description follow these simple rules:
oempty cellxwall (fixed obstacle)Aprimary piece (red car)B - Zall other pieces
I used lowercase o instead of periods . for the empty cells in the database so that the entire board description can be selected with a double-click. My code can parse either format.
Database Download
The database contains every "interesting" 6x6 Rush Hour puzzle with up to two walls. There are 2,577,412 puzzles in the database, covering 9,698,093,879 reachable states. Walls are lowercase x so you can easily grep them in or out as desired.
- Preview the database: rush1000.txt (44K)
- Download bzip2: rush.txt.bz2 (23M)
- Download gzip: rush.txt.gz (33M)
Utilities
My code includes several utility binaries written in Go for solving puzzles, rendering puzzles, etc.
To render a board:
$ go run cmd/render/main.go GBB.L.GHI.LMGHIAAMCCCK.M..JKDDEEJFF. out.png
To create a .dot file for Graphviz and then render it:
$ go run cmd/graph/main.go ..xCCLDD.K.LIAAK..I.JKEEFFJ..MGGGHHM > graph.dot $ dot -Tpng graph.dot > graph.png
To solve a puzzle:
$ go run cmd/solve/main.go GBB.L.GHI.LMGHIAAMCCCK.M..JKDDEEJFF.
{true [F+1 K+1 M-1 C+3 H+2 J-1 E+1 G+3 B-1 I-1 A-3 I+1 L+1 B+3 I-1 A+2 G-3 E-1
H-3 A-1 J+1 C-3 M+1 B+1 K-4 A+1 C+2 D-1 F-1 H+3 A-1 K+1 B-1 M-1 C+1 J-1 E+1 G+3
A-1 I+1 B-3 I-1 A+1 G-1 E-1 J+1 C-1 K-1 L-1 M+3 A+3] 51 81 51 2756 229984}
Negative moves are up or left, positive moves are down or right.
Online Play
I wrote an online version that you can play. I used p5.js to create it. Click "Random" to play a random puzzle from my database.
Try It Yourself
The code is on GitHub at https://github.com/fogleman/rush.
Top 23
The top 23 puzzles in the database require 50 or more moves to solve. Here they are.
Click on one to play it in your browser!
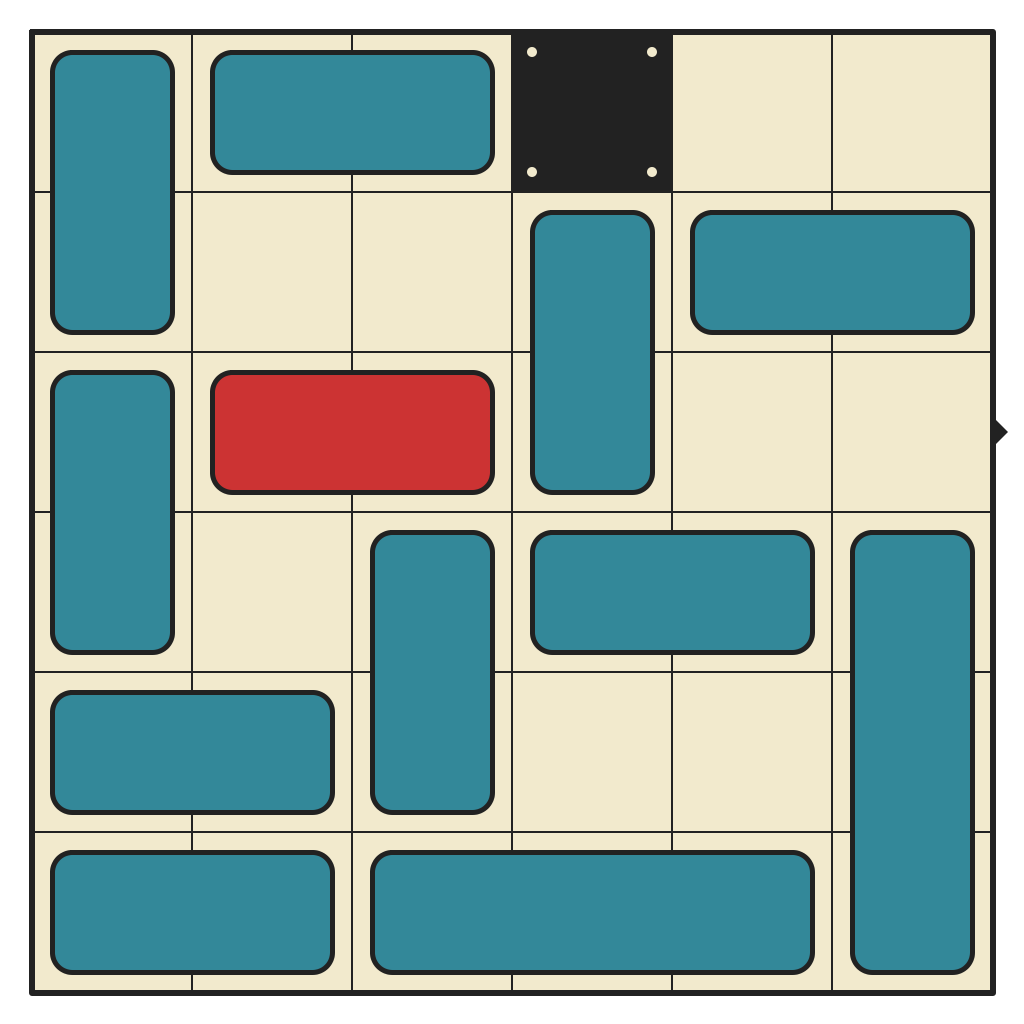
60 moves, 2332 states
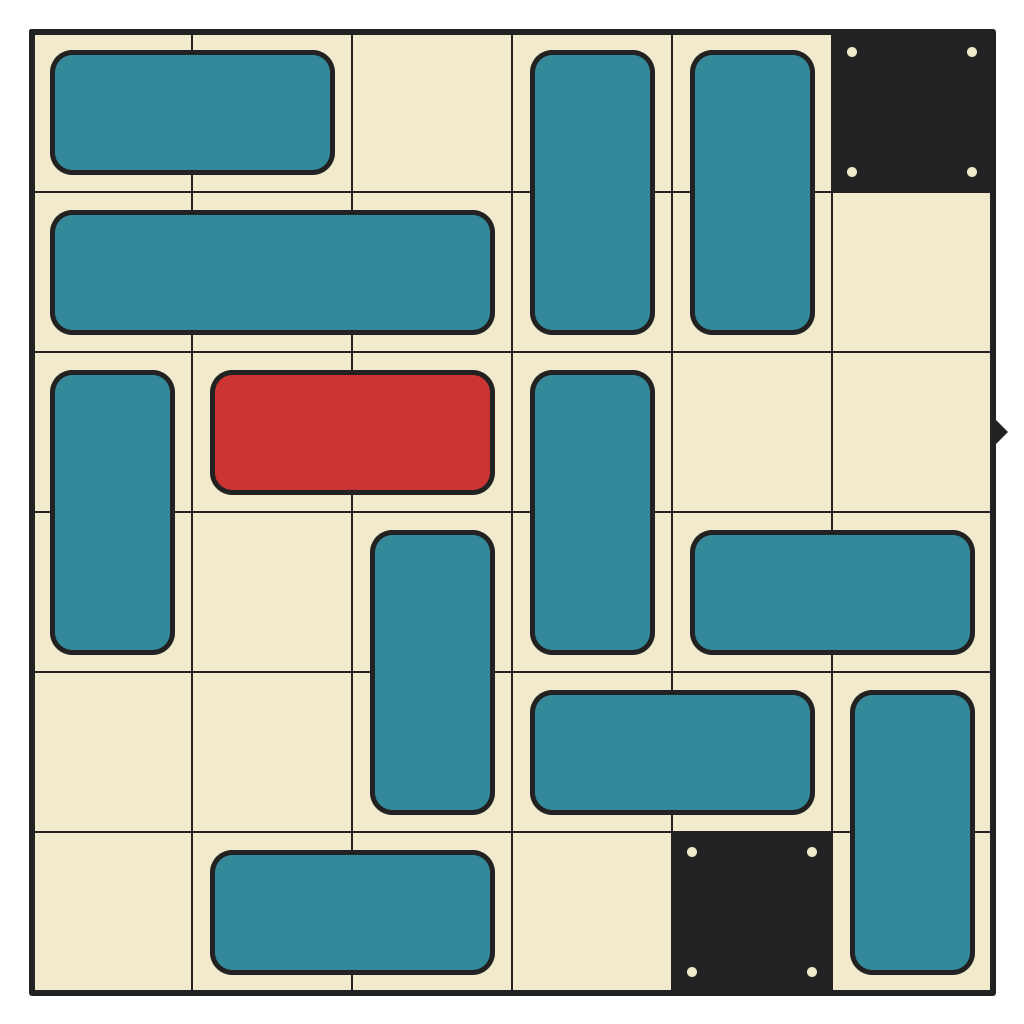
58 moves, 9192 states
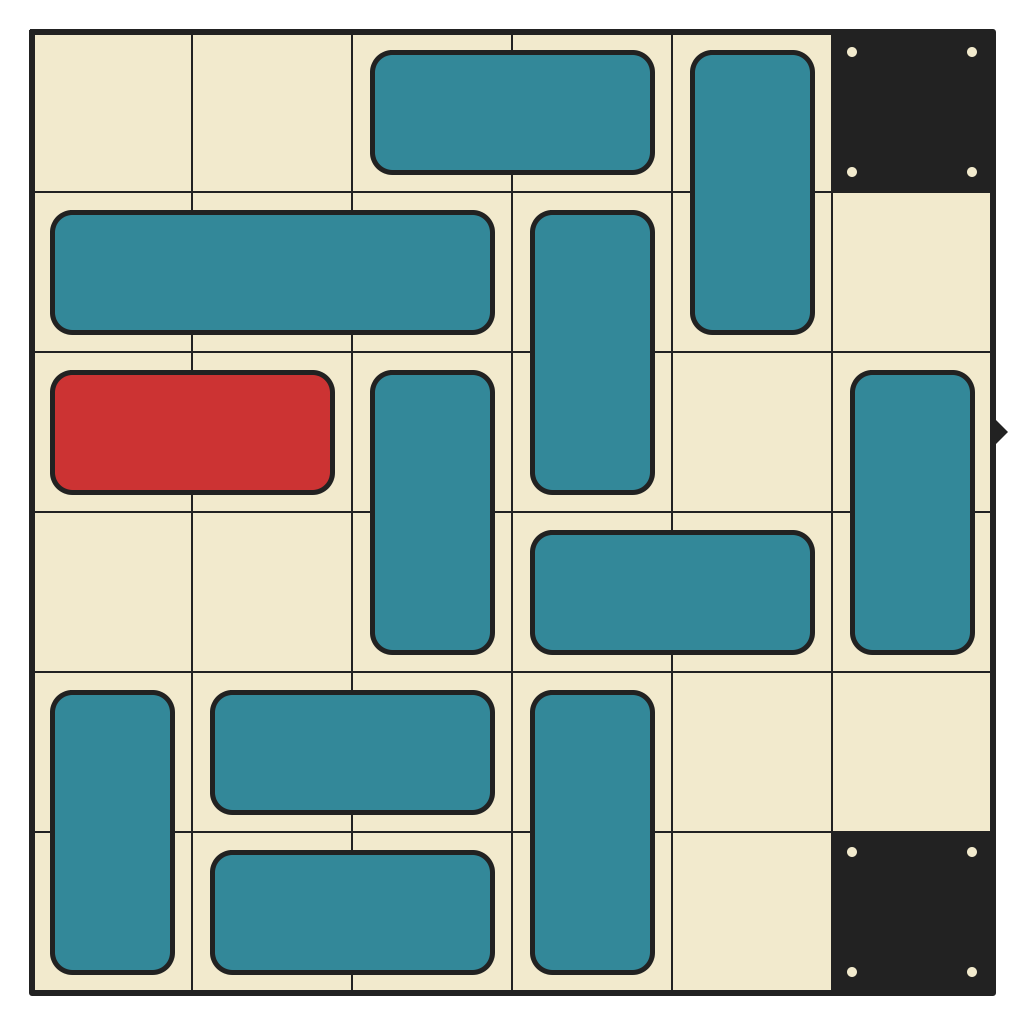
55 moves, 9712 states
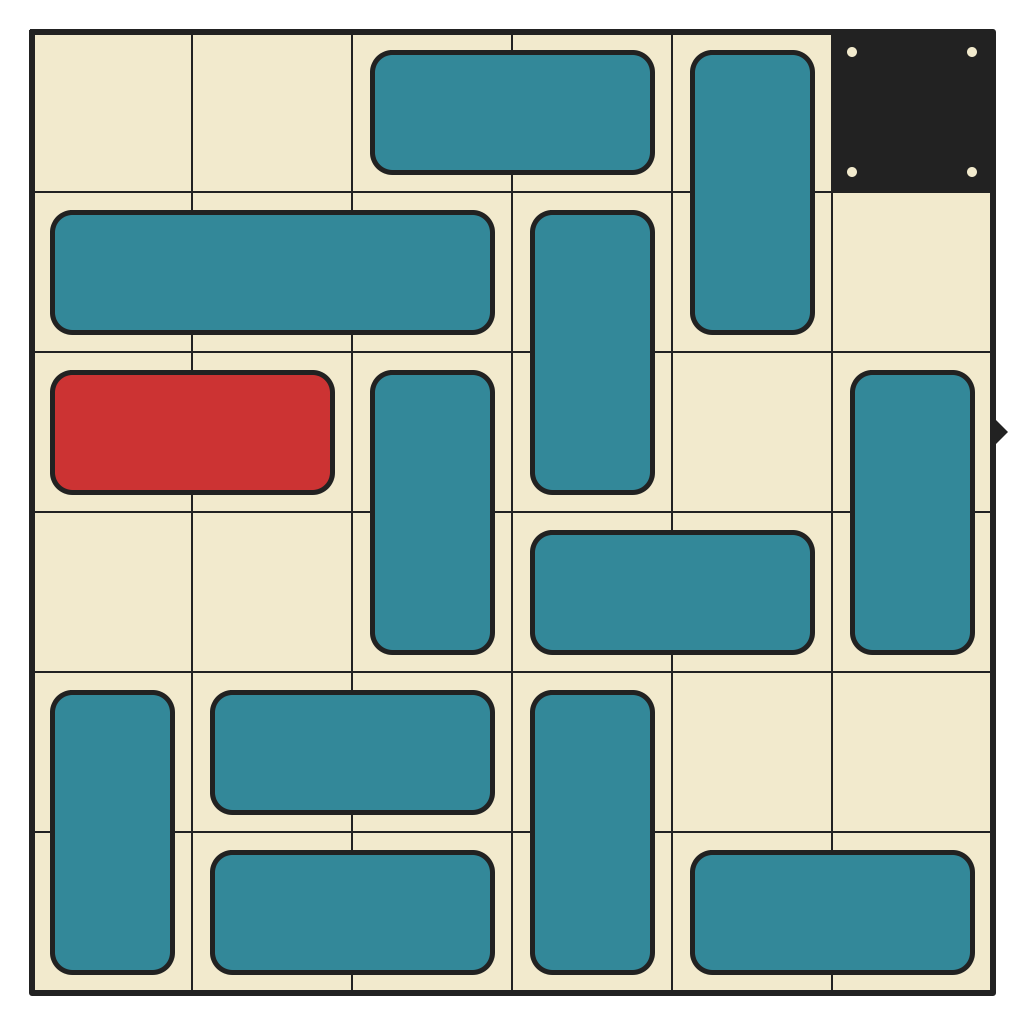
55 moves, 8257 states
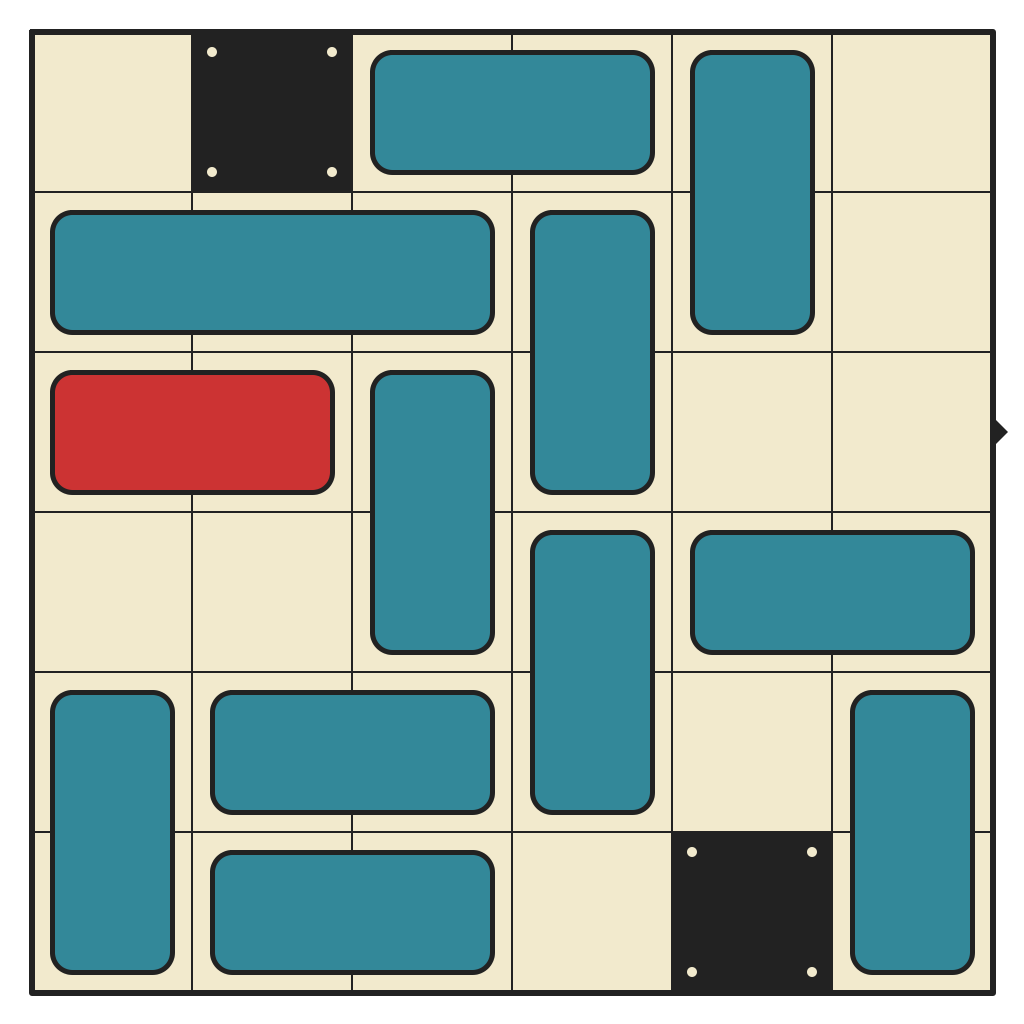
54 moves, 6355 states
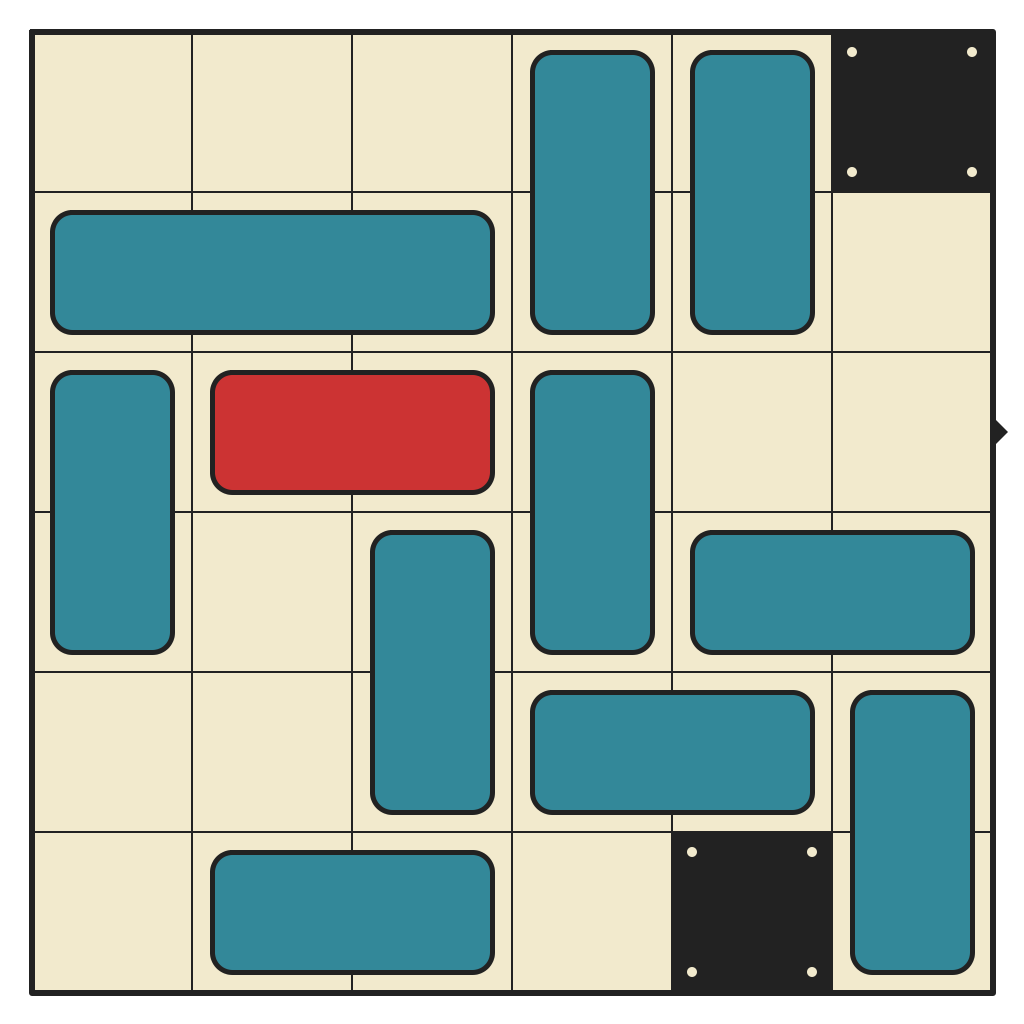
54 moves, 3461 states
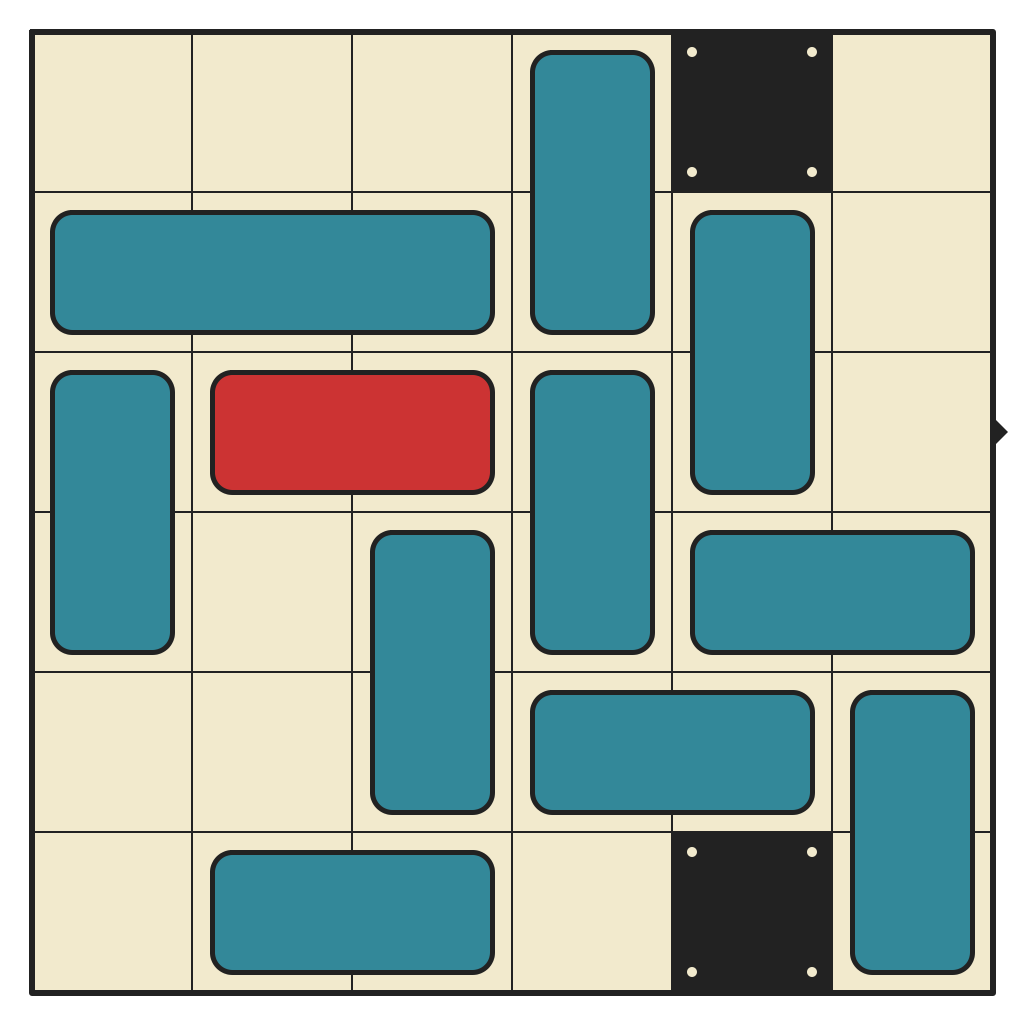
54 moves, 2948 states
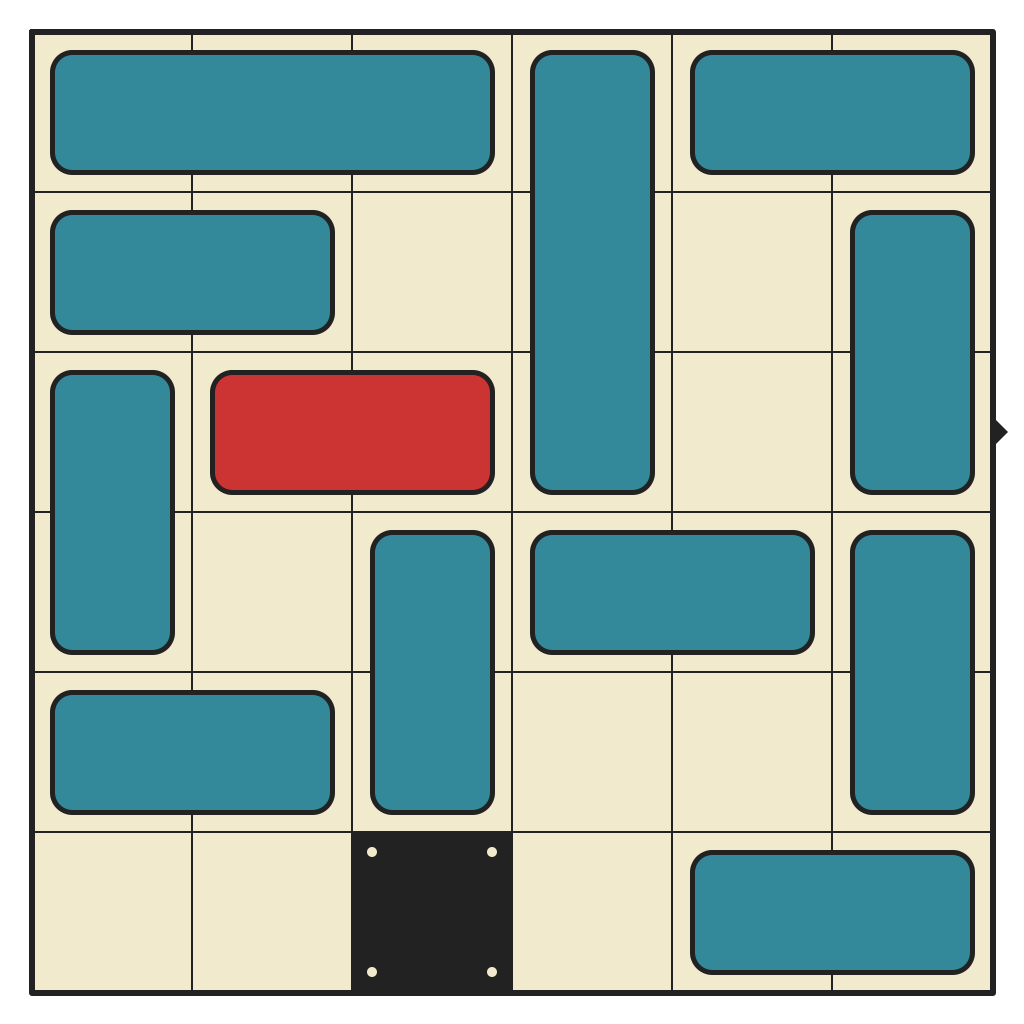
54 moves, 1845 states
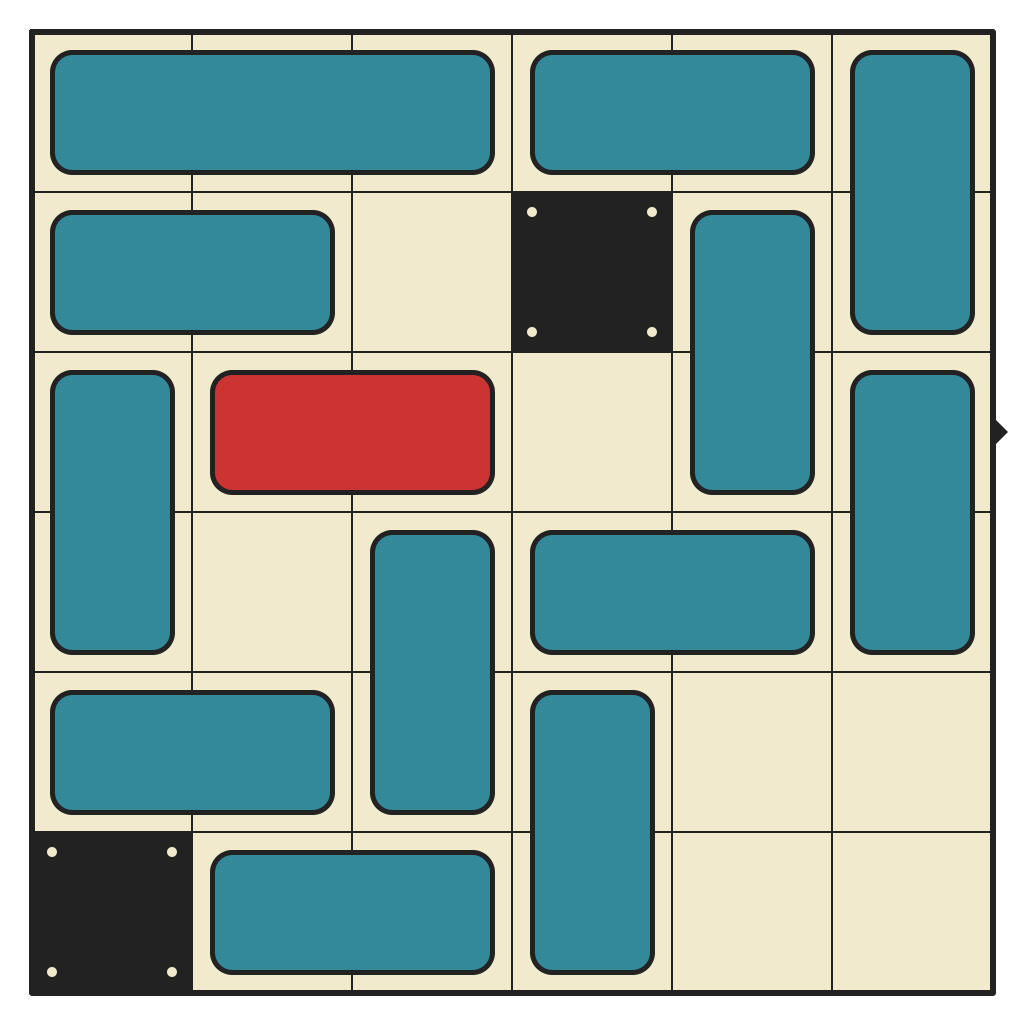
53 moves, 4705 states
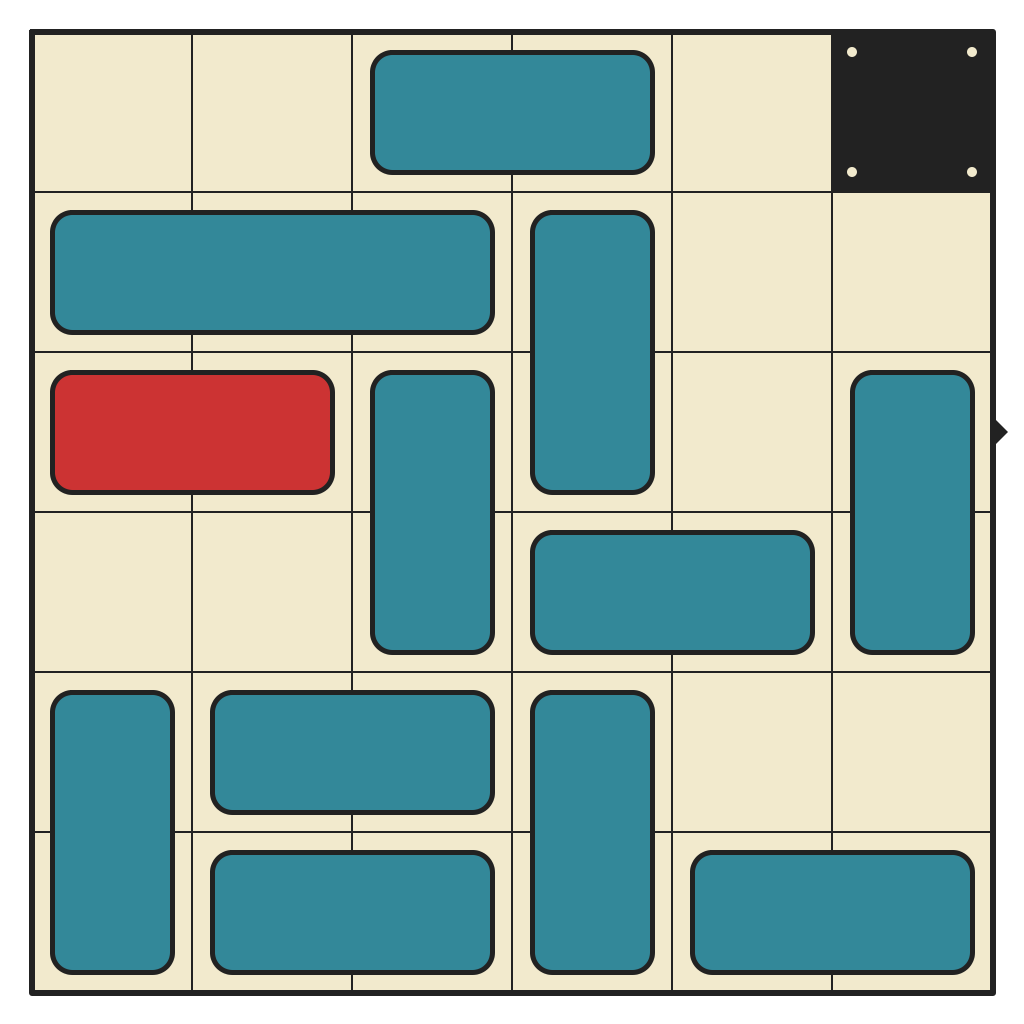
53 moves, 4228 states
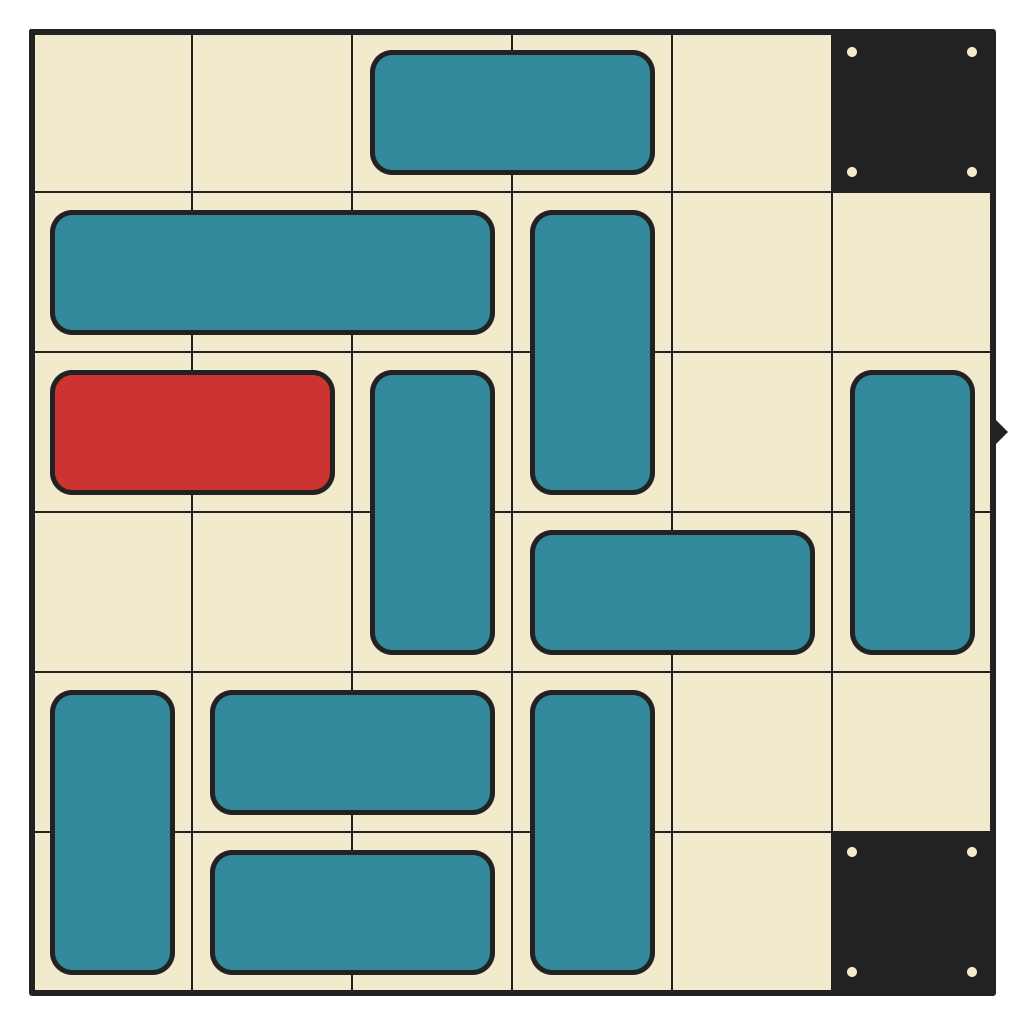
53 moves, 4102 states
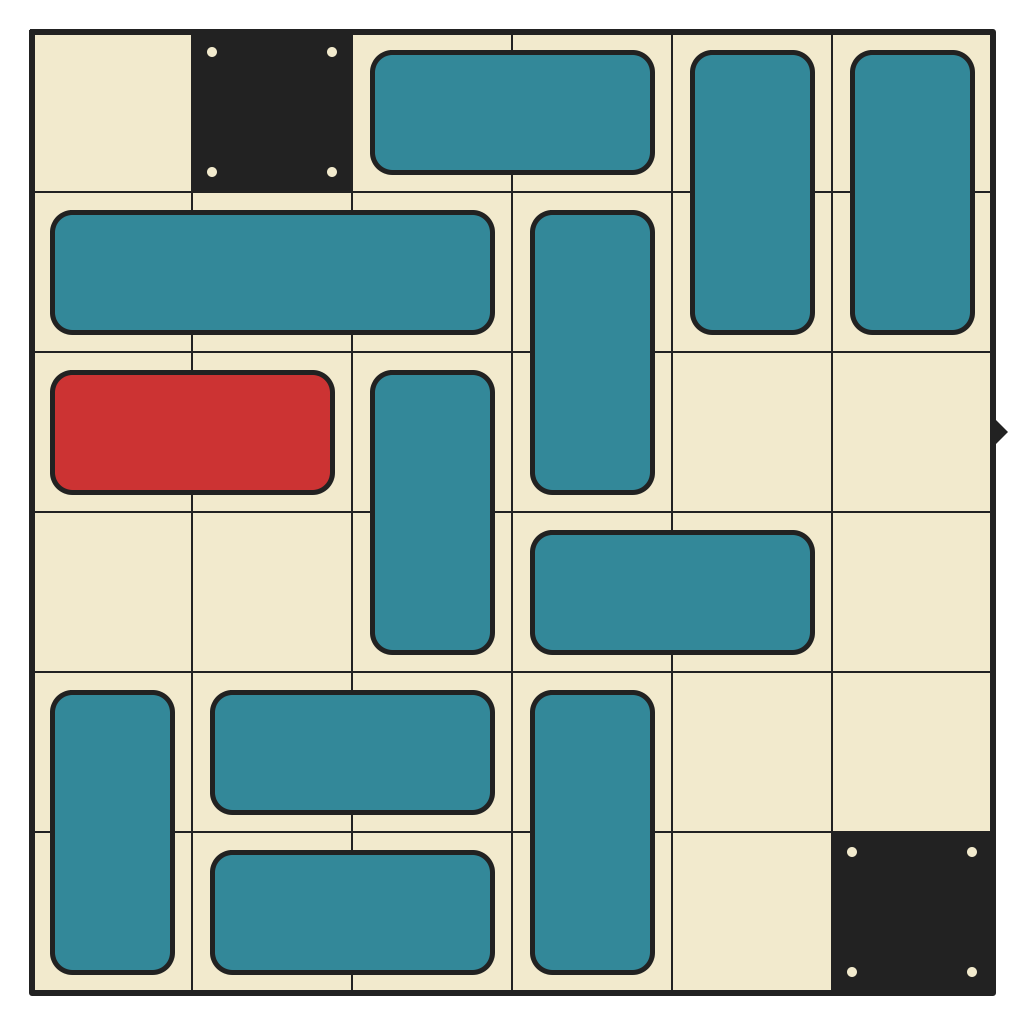
52 moves, 7178 states
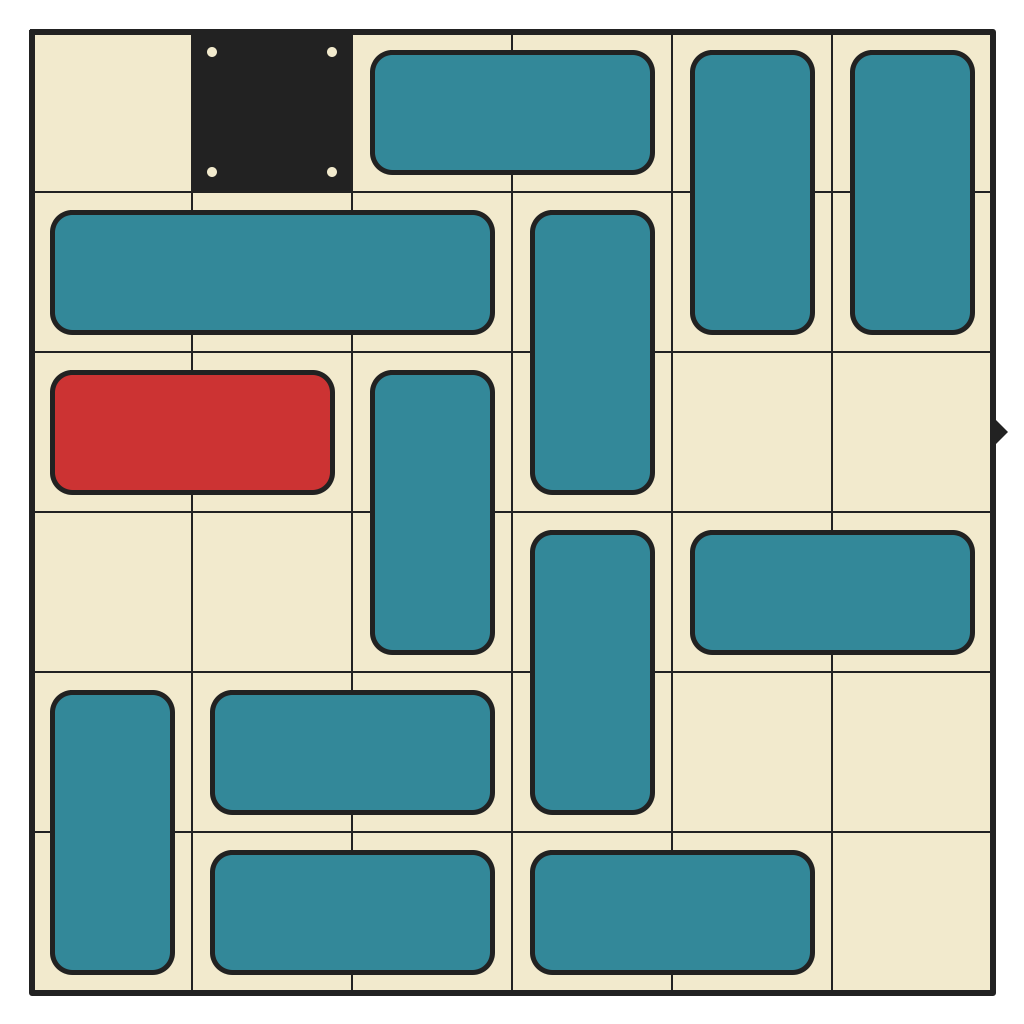
52 moves, 5717 states
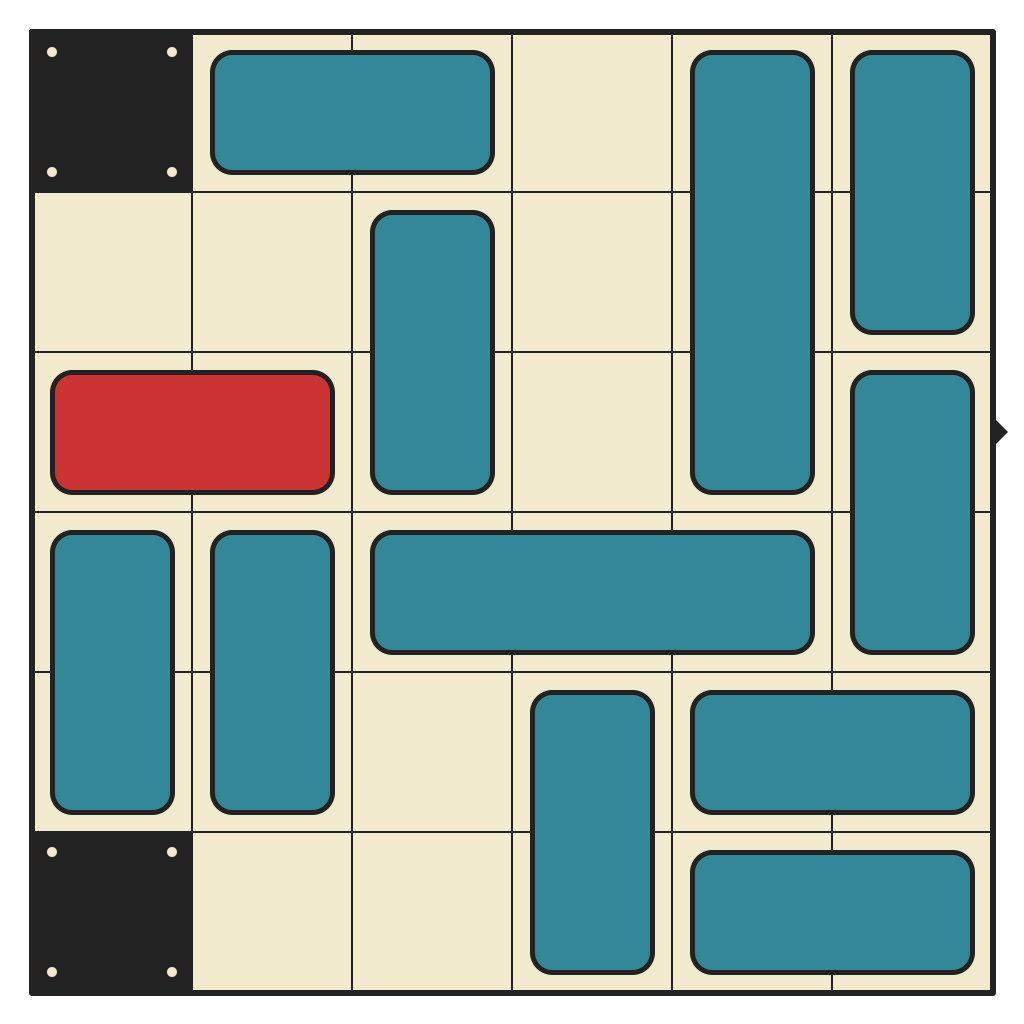
51 moves, 9360 states
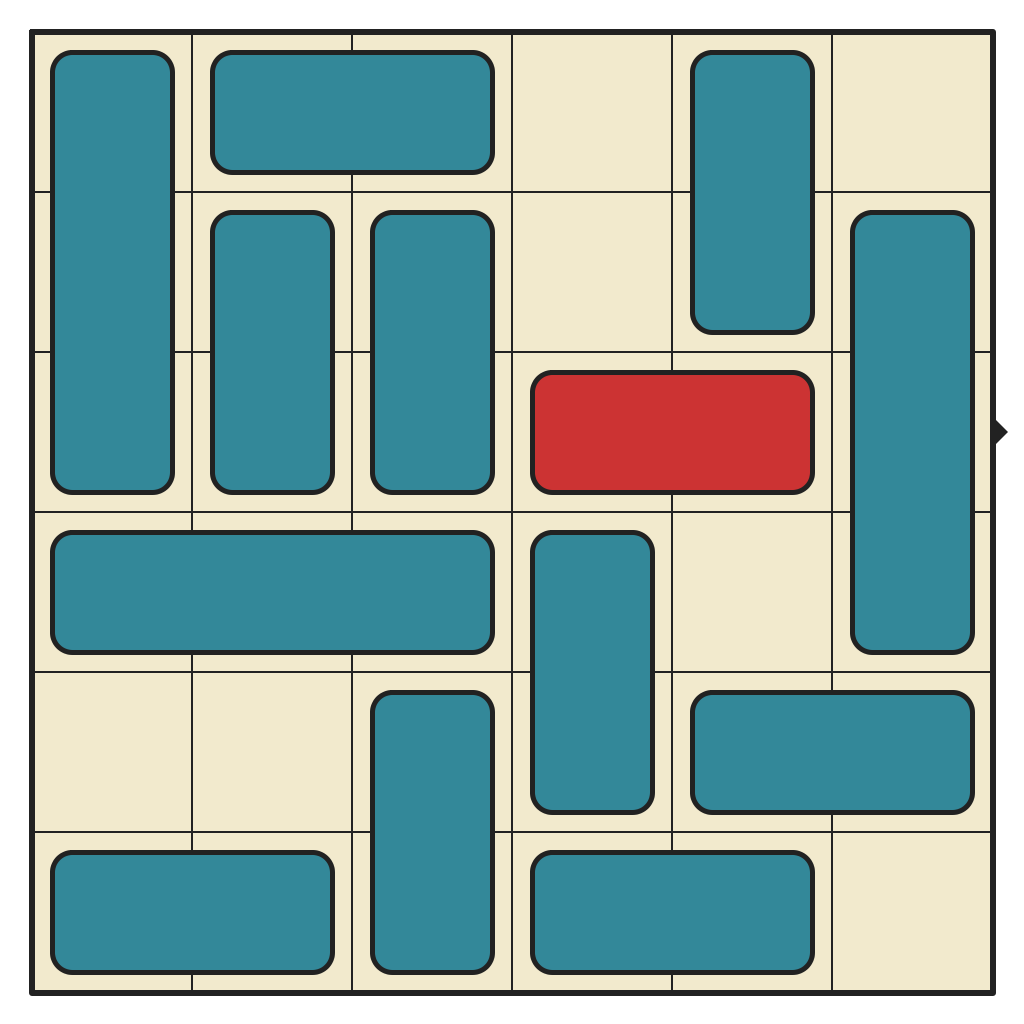
51 moves, 4780 states
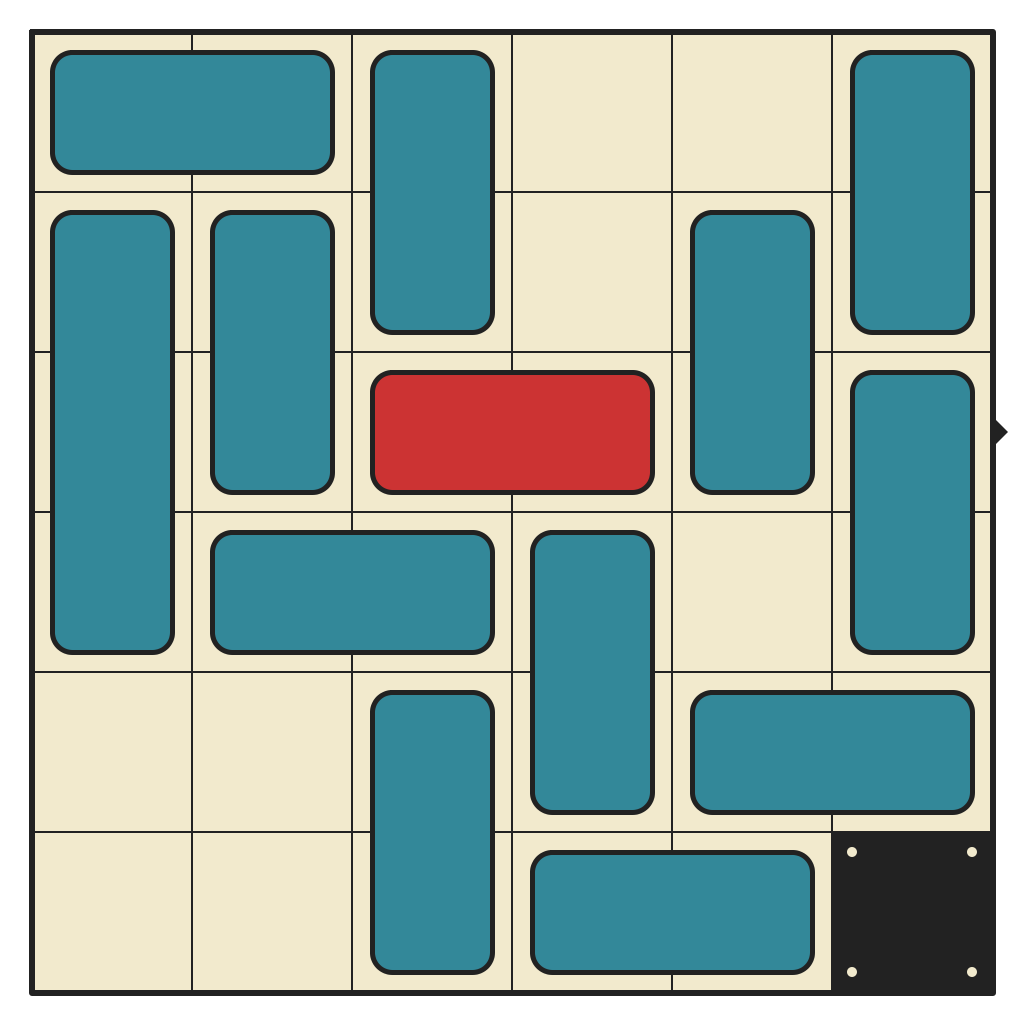
50 moves, 14385 states
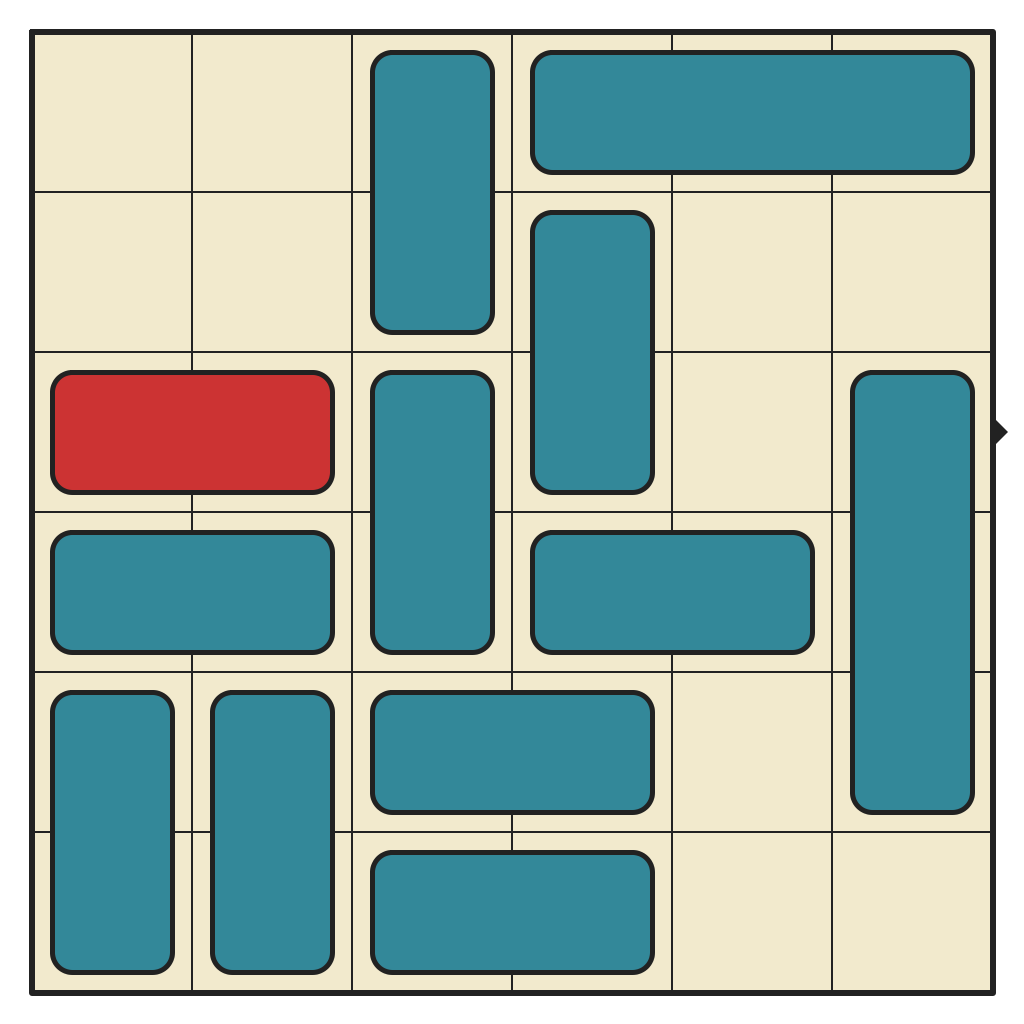
50 moves, 4643 states
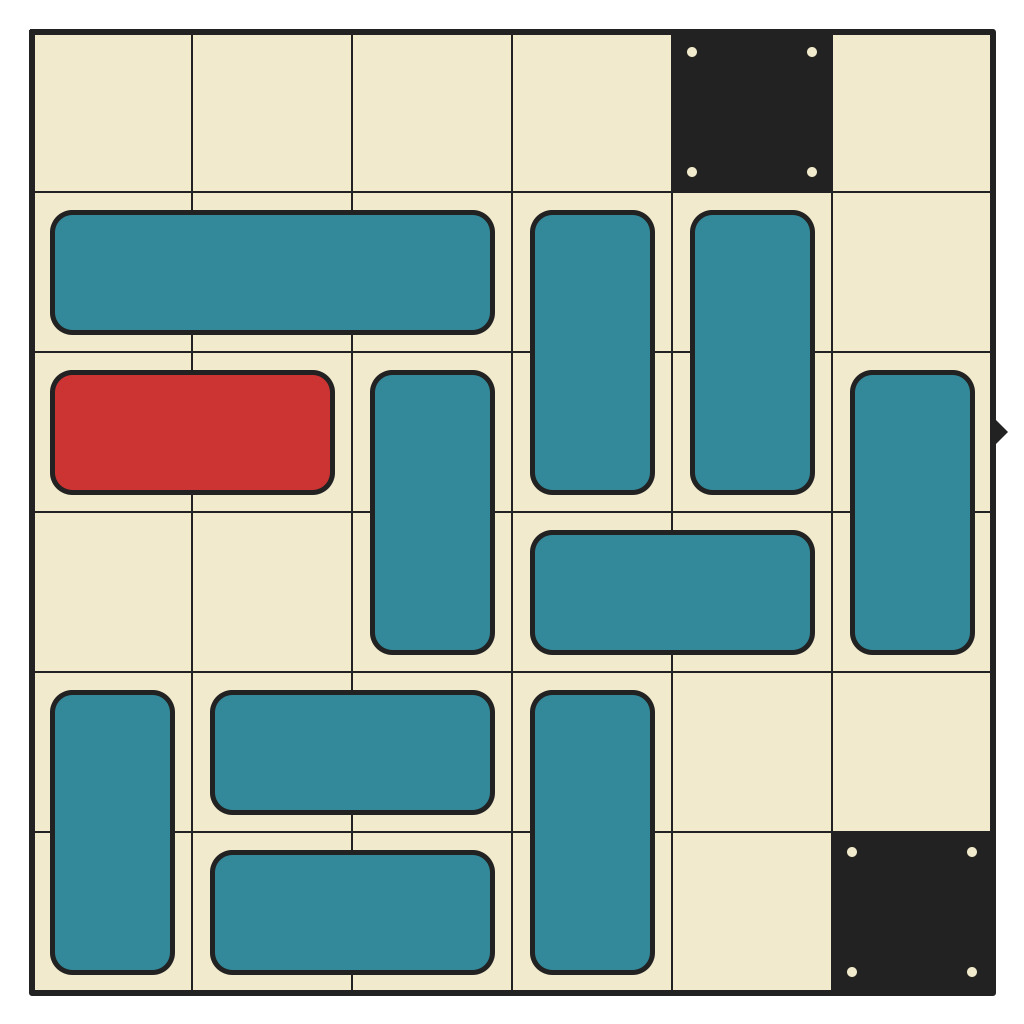
50 moves, 3874 states
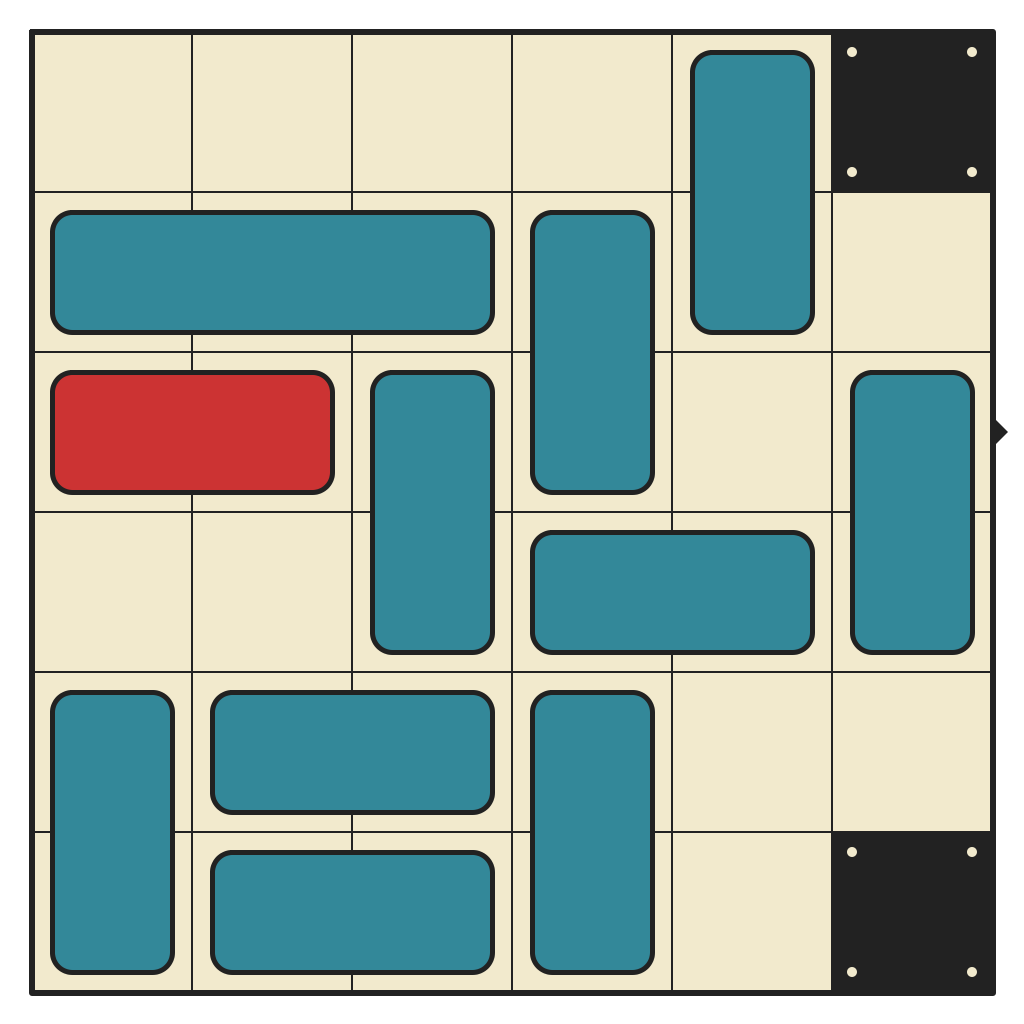
50 moves, 3676 states
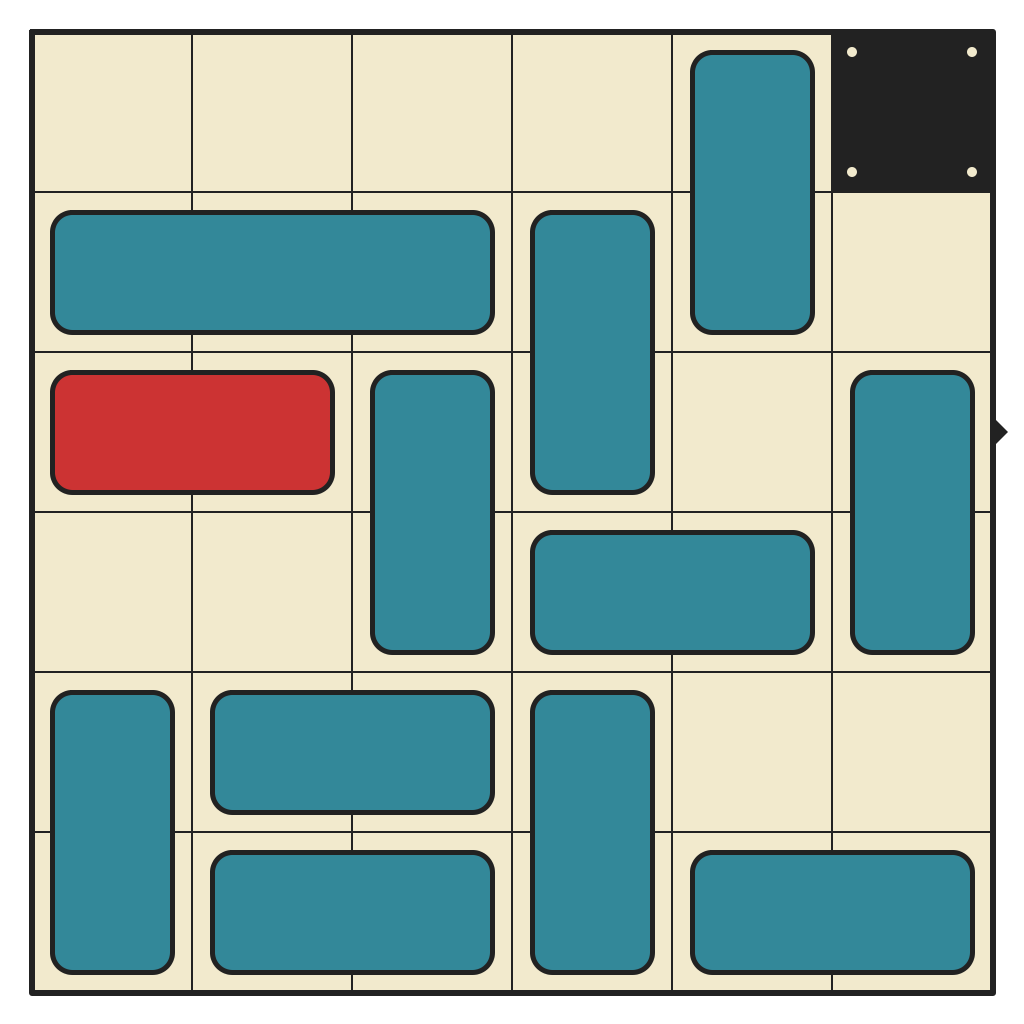
50 moves, 3169 states
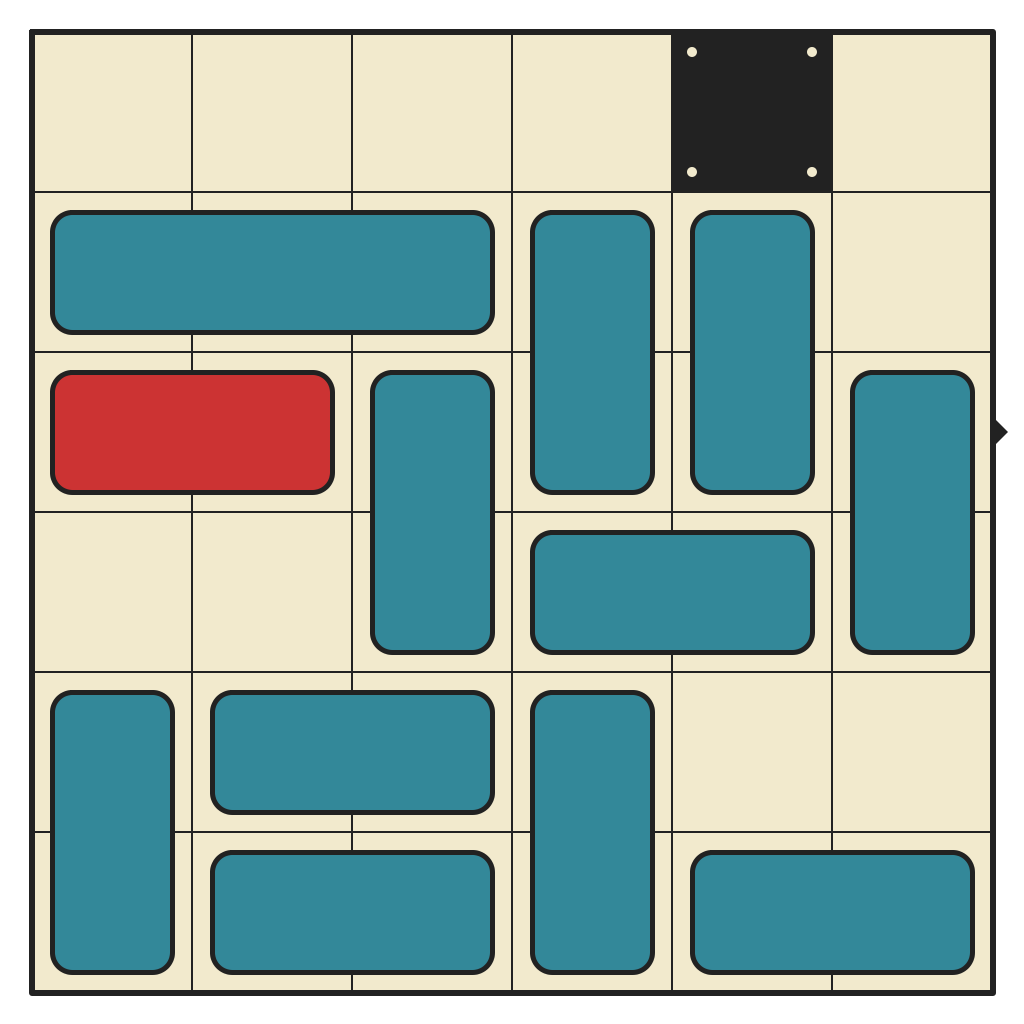
50 moves, 2966 states

50 moves, 1845 states
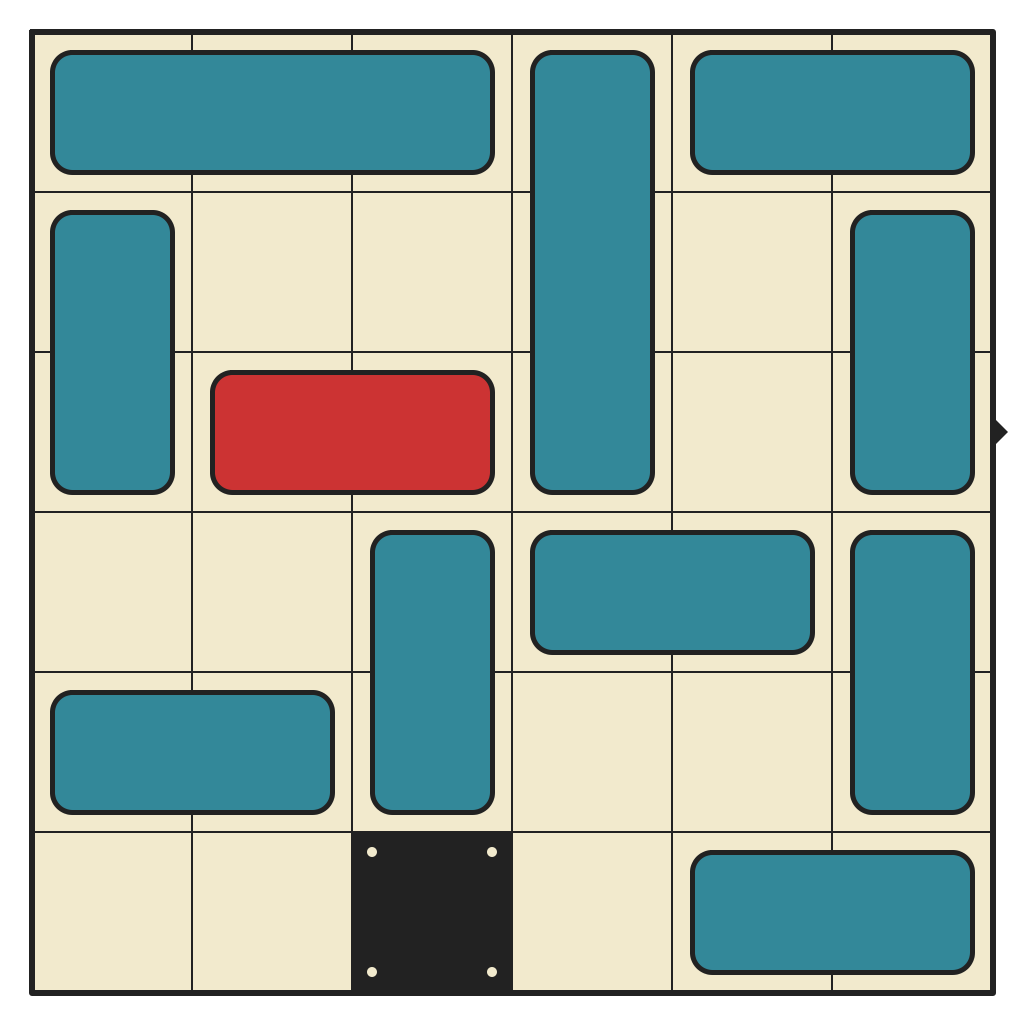
50 moves, 1066 states
Conclusion
I believe that the techniques described in this article advance the current "state of the art" for solving the game of Rush Hour. Prove me wrong and I'll be thrilled!
Let me know if you do anything interesting with the code or the database!